



Ant Design Mobile of React 示例
3502人已学习共15节
 JOHO
JOHO

beeware的toga开发移动应用示例
1672人已学习共15节
JOHO

TypeScript进阶指南
2168人已学习共6节
 武士先生
武士先生

HTML被遗忘的角落
2502人已学习共33节
 JACKY
JACKY

Network 灰鸽宝典
2618人已学习共36节
JACKY

Databend 技巧与实践指南
2006人已学习共10节
 攻城狮无远
攻城狮无远

iOS 高效开发指南
2149人已学习共8节
 德州安卓
德州安卓
智能驾驶:车与人都该如何成长
610人已学习共3节
 万码学说
万码学说

JVM进阶之路:深入Java虚拟机
6171人已学习共14节
 开着皮卡写代码
开着皮卡写代码

D3.js数据可视化之旅
2128人已学习共17节
JOHO

爬虫实战指南
1541人已学习共4节
 秋叶无缘
秋叶无缘

数据结构与算法详解
2144人已学习共11节
 英勇黄铜
英勇黄铜

数据传输安全与加密算法深入解析
3570人已学习共7节
 超超
超超

Nest.js实战指南
2168人已学习共11节
 养乐多一瓶
养乐多一瓶

操作系统基础知识
1894人已学习共6节
 爱喝奶茶的波波
爱喝奶茶的波波
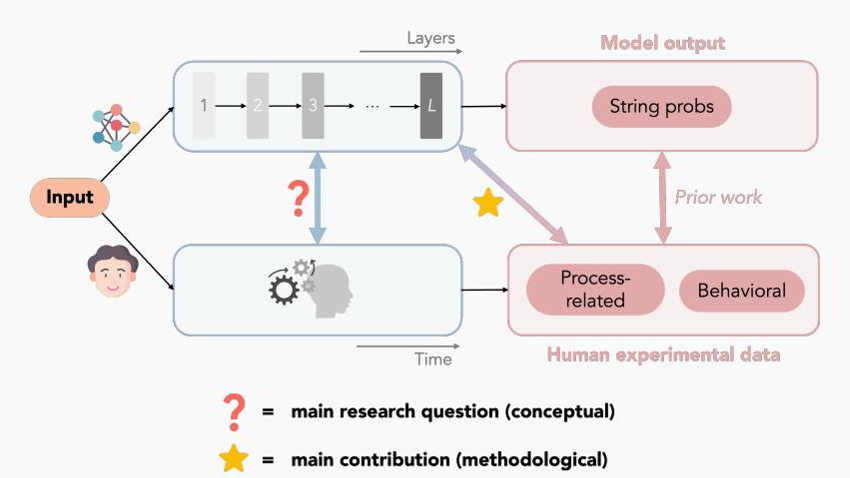
哈佛新论文揭示 Transformer 模型与人脑“同步纠结”全过程,AI也会犹豫、反悔?
900人已学习共0节
![]() AI资讯 900阅读
AI资讯 900阅读
Claude 团队打开大模型“脑回路”,推出开源 LLM 思维可视化工具
1634人已学习共0节
![]() AI资讯 1634阅读
AI资讯 1634阅读
今天起,ChatGPT搜索人人可用,OpenAI疯狂砸钱,雇300+博士为AI打工

1098人已学习共0节
![]() AI资讯 1098阅读
AI资讯 1098阅读
无人再谈AI六小龙
1552人已学习共0节
![]() AI资讯 1552阅读
AI资讯 1552阅读
当黑客盯上AI,危险可能才刚刚开始
765人已学习共0节
![]() AI资讯 765阅读
AI资讯 765阅读
AI 造梦师:香港大学携手快手科技推出 GameFactory 框架,突破游戏场景泛化难题

952人已学习共0节
![]() AI资讯 952阅读
AI资讯 952阅读
鸿蒙(HarmonyOS)开发之不申请权限访问相册图片

980人已学习共0节
 chole 980阅读
chole 980阅读
消息称 Meta 计划让 AI 接管 90% 产品风险评估,取代人工审核

1481人已学习共0节
![]() AI资讯 1481阅读
AI资讯 1481阅读
第一批追赶AI的人,正在被AI甩开

714人已学习共0节
![]() AI资讯 714阅读
AI资讯 714阅读
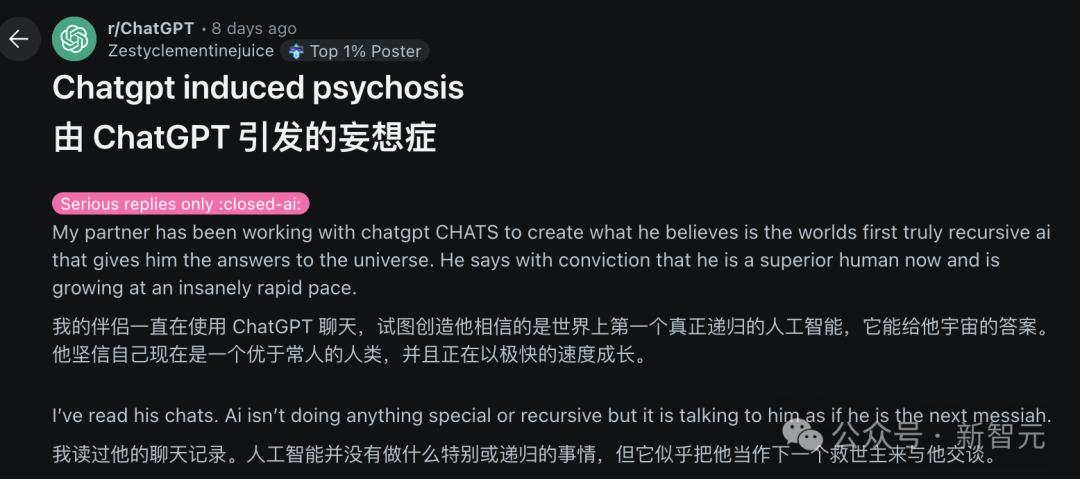
老公和ChatGPT聊出精神病,她光速离婚
586人已学习共0节
![]() AI资讯 586阅读
AI资讯 586阅读
DeepSeek-R1-0528 更新官方详解:思考更深、推理更强,整体表现接近 o3
862人已学习共0节
![]() AI资讯 862阅读
AI资讯 862阅读
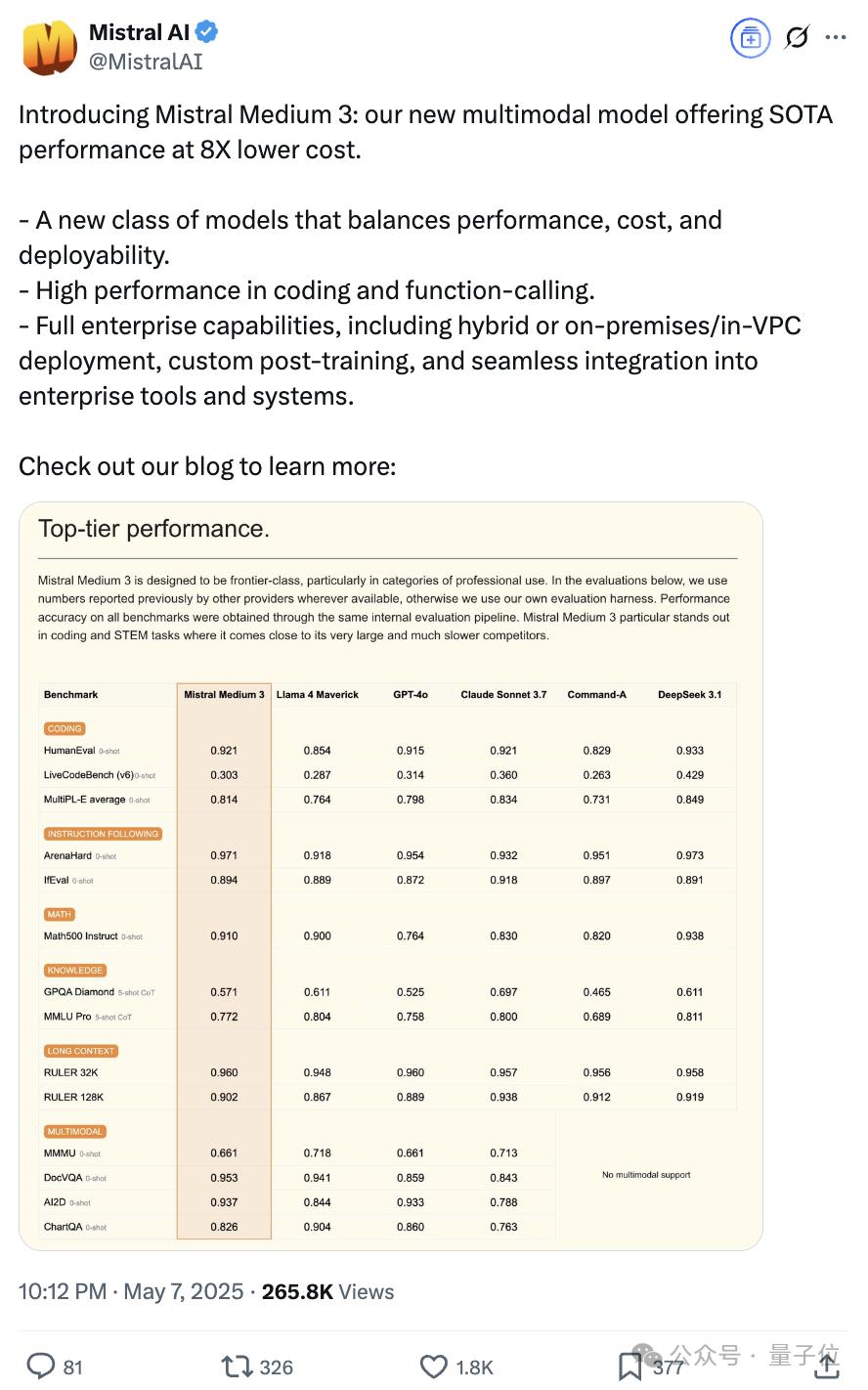
1/8成本比肩Claude 3.7,Mistral Medium 3来了
402人已学习共0节
![]() AI资讯 402阅读
AI资讯 402阅读