分享
点赞
18
评论
0

DeepSeek-R1
92015星
DeepSeek-R1系列以大规模强化学习为基础,实现自主推理,表现卓越,推理行为强大且独特。开源共享,助力研究社区深入探索LLM推理能力,推动行业发展。
项目来源:
项目简介
1、介绍:
第一代推理模型,DeepSeek-R1-Zero和DeepSeek-R1。DeepSeek-R1-Zero是一个通过大规模强化学习(RL)训练的模型,没有监督微调(SFT)作为初步步骤,在推理方面表现出了出色的表现。有了RL,DeepSeek-R1-Zero自然而然地出现了许多强大而有趣的推理行为。然而,DeepSeek-R1-Zero遇到了挑战,如无休止的重复、可读性差和语言混合。为了解决这些问题并进一步提高推理性能,我们引入了DeepSeek-R1,它包含RL之前的冷启动数据。DeepSeek-R1在数学、代码和推理任务方面实现了与OpenAI-o1相当的性能。为了支持研究界,我们开源了DeepSeek-R1-Zero、DeepSeek-R1以及基于Llama和Qwen的DeepSeek-R1提炼的六个密集模型。DeepSeek-R1-Distill-Qwen-32B在各种基准上都优于OpenAI-o1-mini,为密集模型实现了新的最先进的结果。
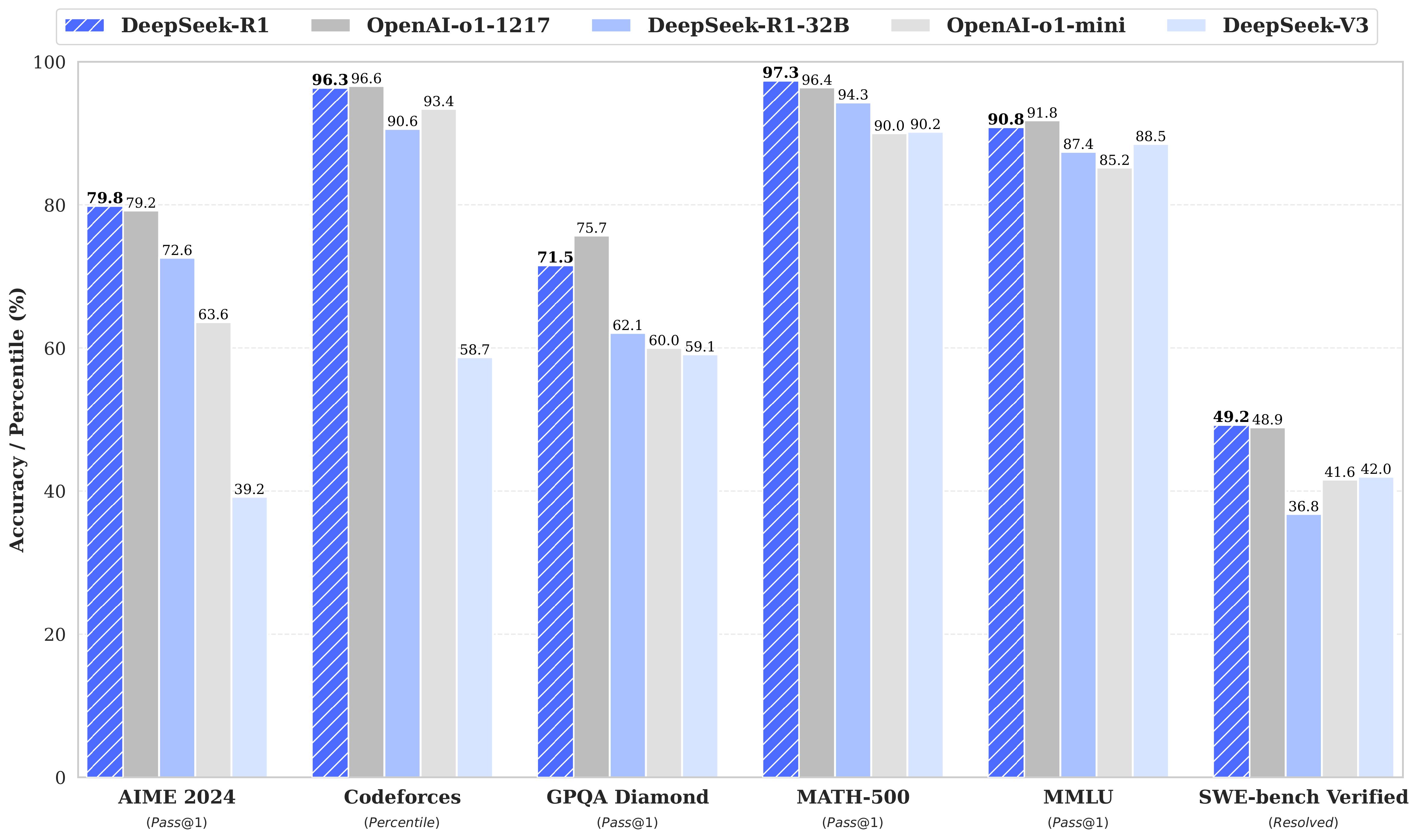
2、模型总结:
训练后:基础模型上的大规模强化学习
- 我们直接将强化学习(RL)应用于基础模型,而不依赖监督微调(SFT)作为初步步骤。这种方法允许模型探索思想链(CoT)来解决复杂问题,从而开发了DeepSeek-R1-Zero。DeepSeek-R1-Zero展示了自我验证、反思和生成长CoT等功能,标志着研究界的一个重要里程碑。值得注意的是,这是第一项公开研究,验证了LLM的推理能力可以纯粹通过RL获得激励,而不需要SFT。这一突破为该领域未来的进步铺平了道路。
- 我们介绍开发DeepSeek-R1的管道。该管道包含两个RL阶段,旨在发现改进的推理模式并与人类偏好保持一致,以及两个SFT阶段,作为模型推理和非推理能力的种子。我们相信,管道将通过创造更好的模型来造福行业。
蒸馏:较小的模型也可以更强大
- 我们证明,与通过RL在小型模型上发现的推理模式相比,大型模型的推理模式可以提炼成较小的模型,从而产生更好的性能。开源的DeepSeek-R1及其API将有利于研究界在未来提炼出更好的小型模型。
- 使用DeepSeek-R1生成的推理数据,我们微调了几个在研究界广泛使用的密集模型。评估结果表明,蒸馏的较小密度模型在基准上表现特别好。我们基于Qwen2.5和Llama3系列向社区开源蒸馏了1.5B、7B、8B、14B、32B和70B检查点。