李宏毅《深度学习》(二)-灵析社区
 我不是魔法师
我不是魔法师3-回归

线性回归的定义
线性回归的定义是:目标值预期是输入变量的线性组合。简单来说,就是选择一条线性函数来很好的拟合已知数据并预测未知数据。
回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析。
应用举例
- 股市预测(Stock market forecast)
- 自动驾驶(Self-driving Car)
- 商品推荐(Recommendation)
- Pokemon精灵攻击力预测(Combat Power of a pokemon):
模型步骤讲解
- step1:模型假设,选择模型框架(线性模型)
- step2:模型评估,如何判断众多模型的好坏(损失函数)
- step3:模型优化,如何筛选最优的模型(梯度下降) 这个并不是完成一个机器学习任务的步骤,对上述step的理解是:选择一个模型框架,然后开始训练,评价模型好坏我们使用损失函数评价,为了使损失函数最小,我们使用了梯度下降法来求得损失函数的最小值。要完成一个机器学习任务,需要完成以下的步骤:
- 数据收集:此步骤至关重要,因为所收集数据的质量和数量将有助于提高预测模型的准确性。
- 数据准备:一旦收集了数据,就需要将其加载到系统中,并为机器学习训练做好准备,但是有的时候我们收集到的数据可能会有较多无用的特征,或者是干扰项,我们要根据实际情况和需求对特征或者数据量进行相应的增加或者删除。
- 选择合适的模型:根据我们对任务的理解以及经验,选择合适的训练模型。
- 训练模型:使用数据进一步改善了模型的性能,对模型进行训练。
- 评价模型:评价过程需要检查模型是否得到有效的训练或是否可以完成任务。通过这种方法,您可以轻松用训练中未出现过的数据来测试模型。这样是为了测试模型如何响应尚未遇到的数据,进行评价是为了分析模型的适应能力。
- 超参数调整:这是为了检查正在训练的模型是否仍有改进的余地。可以通过调整某些参数(学习率或在训练过程中训练模型运行的次数)来实现。在训练期间,你要考虑多个参数。对于每个参数,你要知道它们在模型训练中所起的作用,否则您可能会发现自己在浪费时间或经过调参后耗时更长了。
- 预测:最后一步,一旦遵循了上述参数,就可以对模型进行测试。
Step 1:模型假设 - 线性模型
一元线性模型(单个特征)
定义: 也叫一元线性回归,一元线性回归是分析只有一个自变量。从一个输入值预测一个输出值,输入/输出的对应关系就是一个线性函数。

多元线性模型(多个特征)
定义: 在回归分析中,如果有两个或两个以上的自变量,就称为多元回归。当样本的描述涉及多个属性时,这类问题就被称为多元线性回归。



Step 2:模型评估 - 损失函数
定义: 损失函数 (Loss Function) 也可称为代价函数 (Cost Function)或误差函数(Error Function),用于衡量预测值与实际值的偏离程度。一般来说,我们在进行机器学习任务时,使用的每一个算法都有一个目标函数,算法便是对这个目标函数进行优化,特别是在分类或者回归任务中,便是使用损失函数(Loss Function)作为其目标函数。机器学习的目标就是希望预测值与实际值偏离较小,也就是希望损失函数较小,也就是所谓的最小化损失函数。

该损失函数的意义就是,当预测错误时,损失函数值为1,预测正确时,损失函数值为0。该损失函数不考虑预测值和真实值的误差程度,也就是只要预测错误,预测错误差一点和差很多是一样的。

该损失函数的意义和上面差不多,只不过是取了绝对值而不是求绝对值,差距不会被平方放大。
- 对数损失函数(logarithmicloss function)或对数似然损失函数(log-likelihood loss function)

Step 3:最佳模型 - 梯度下降。
梯度下降是迭代法的一种,是解决求解线性和非线性最小二乘问题的方法之一。经常用于求解损失函数的最小值,通过梯度下降法来一步步地迭代求解,得到最小化的损失函数和模型参数值。

其中有一个问题:为什么要乘-k
答:我们要找最小梯度,换而言之就是找函数的最低点,如果可以用数学思维来解释,对当前点求微分,如果导数小于0,表示最低点在该点的右侧,导数为负数,乘-k即为增加w的值,若导数大于0,表示最低点在该点的左侧,导数为正数,乘-k即为减小w的值。
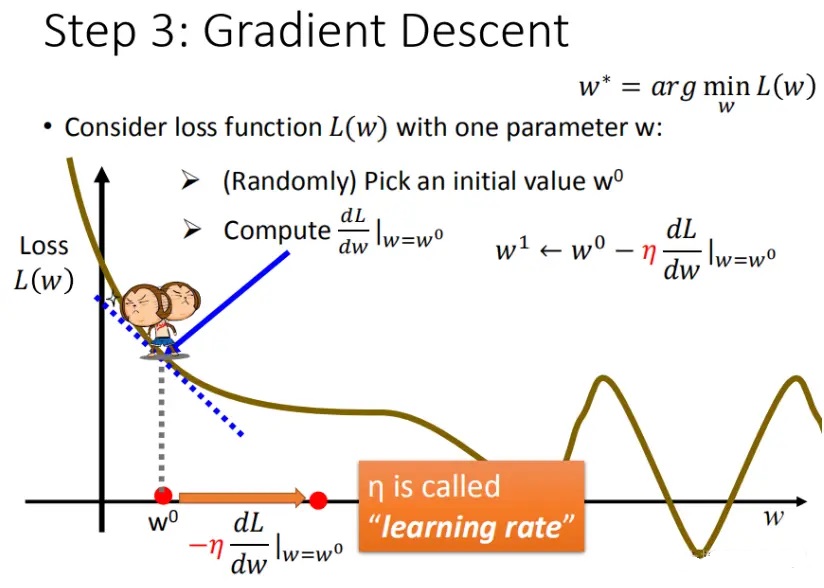


学习率或者步长设置的合理的情况

学习率或步长设置一般的情况,会在最小值点附近来回变化,可以采用更新学习率的方法,不断接近最小值

学习率或步长设置不合理的情况,最终结果发散,得不到最小值
实际上在学习过程中,我们应该将学习率的数值随之迭代次数的增加而逐步减小
但是有的时候会存在这么一个问题,你当前达到的最优点,不一定是你的全局最优点,而可能是局部最优点,如下图所示:
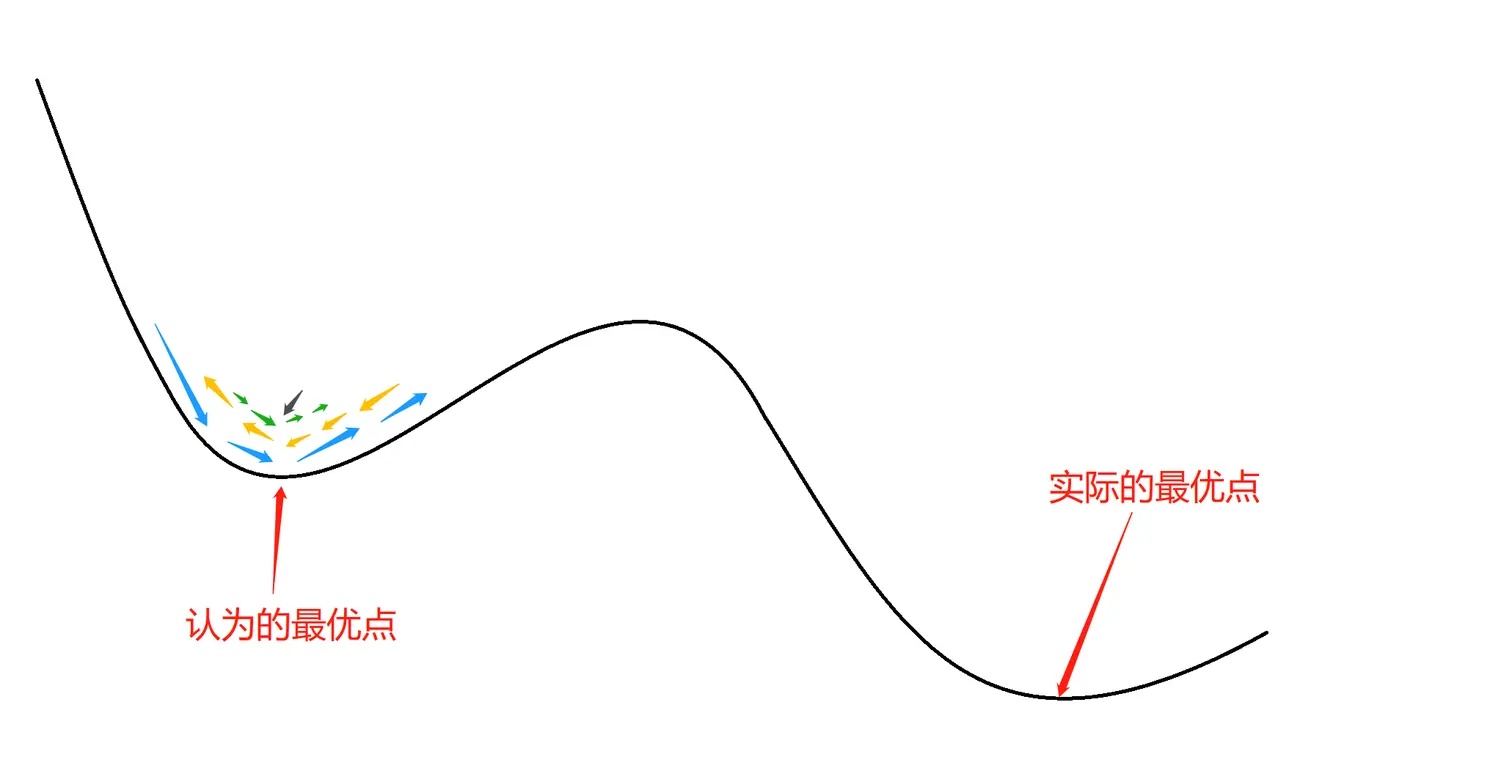
现实任务中,人们常采用以下策略来试图“跳出”局部最小值,从而达到全局最小值:
- 以多组不同参数值初始化多个神经网络,按标准方法训练后,取其中误差最小的解作为最终参数,这相当于从多个不同的初始化点开始搜索,从而可能寻找全局最优。
- 使用模拟退化技术,模拟退火在每一步都以一定的概率接受比当前解更差的结果,从而有助于“跳出”局部极小。在每步迭代过程中,接受“次优解”的概率随着时间的推移而逐渐降低,从而保证算法的稳定。
- 使用随机梯度下降,与标准的梯度下降法精确计算梯度不同,随机梯度下降法在计算梯度时加入了随机的因素。于是,即便陷入局部极小点,它计算出的梯度时加入了随机因素,于是,即便陷入局部极小点,它计算出的梯度可能不为0,这样就有机会跳出局部极小继续搜索。
如何验证模型好坏
- 划分训练集和测试集
- 评价分类结果:精准度、混淆矩阵、精准率、召回率、F1 Score、ROC曲线等
- 评价回归结果:MSE、RMSE、MAE、R Squared
过拟合问题出现
在模型上,我们再可以进一部优化,使用更高次方的模型。但是会发现在训练集上面表现更为优秀的模型,为什么在测试集上效果反而变差了?这就是模型在训练集上过拟合的问题。
将错误率结果图形化展示,发现3次方以上的模型,已经出现了过拟合的现象:

随着训练过程的进行,模型复杂度,在training data上的error渐渐减小。可是在验证集上的error却反而渐渐增大——由于训练出来的网络过拟合了训练集,对训练集以外的数据却不work。
在机器学习算法中,我们经常将原始数据集分为三部分:训练集(training data)、验证集(validation data)、测试集(testing data)。
问题:验证集是什么?
它事实上就是用来避免过拟合的。在训练过程中,我们通经常使用它来确定一些超參数(比方,依据validation data上的accuracy来确定early stopping的epoch大小、依据validation data确定learning rate等等)。那为啥不直接在testing data上做这些呢?由于假设在testing data做这些,那么随着训练的进行,我们的网络实际上就是在一点一点地过拟合我们的testing data,导致最后得到的testing accuracy没有什么參考意义。因此,training data的作用是计算梯度更新权重,testing data则给出一个accuracy以推断网络的好坏。
防止过拟合方法主要有:
- 正则化(Regularization)(L1和L2)
- 数据增强(Data augmentation),也就是增加训练数据样本
- Dropout
步骤优化
Step1优化:2个input的四个线性模型是合并到一个线性模型中
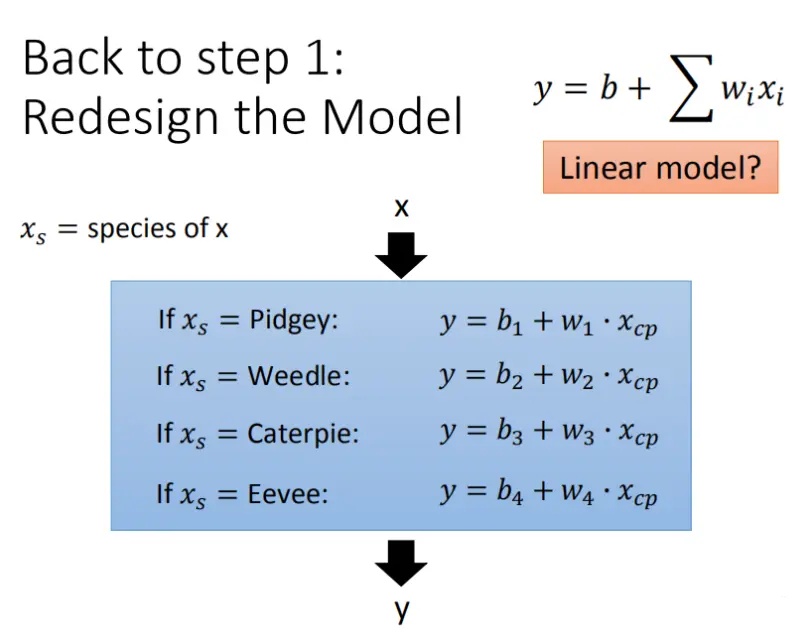

Step2优化:如果希望模型更强大表现更好(更多参数,更多input)
在最开始我们有很多特征,图形化分析特征,将血量(HP)、重量(Weight)、高度(Height)也加入到模型中
Step3优化:加入正则化
更多特征,但是权重 w 可能会使某些特征权值过高,仍旧导致overfitting,所以加入正则化
- w 越小,表示 function较平滑的,function输出值与输入值相差不大
- 在很多应用场景中,并不是w越小模型越平滑越好,但是经验值告诉我们w越小大部分情况下都是好的。
- b 的值接近于0 ,对曲线平滑是没有影响
4-回归演示
import numpy as np
import matplotlib.pyplot as plt
from pylab import mpl
# matplotlib没有中文字体,动态解决
plt.rcParams['font.sans-serif'] = ['Simhei'] # 显示中文
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
x_data = [338., 333., 328., 207., 226., 25., 179., 60., 208., 606.]
y_data = [640., 633., 619., 393., 428., 27., 193., 66., 226., 1591.]
x_d = np.asarray(x_data)
y_d = np.asarray(y_data)
x = np.arange(-200, -100, 1)
y = np.arange(-5, 5, 0.1)
Z = np.zeros((len(x), len(y)))
X, Y = np.meshgrid(x, y)
# loss
for i in range(len(x)):
for j in range(len(y)):
b = x[i]
w = y[j]
Z[j][i] = 0 # meshgrid吐出结果:y为行,x为列
for n in range(len(x_data)):
Z[j][i] += (y_data[n] - b - w * x_data[n]) ** 2
Z[j][i] /= len(x_data)
# linear regression
# b = -120
# w = -4
b = -2
w = 0.01
lr = 0.000005
iteration = 1400000
b_history = [b]
w_history = [w]
loss_history = []
import time
start = time.time()
for i in range(iteration):
m = float(len(x_d))
y_hat = w * x_d + b
loss = np.dot(y_d - y_hat, y_d - y_hat) / m
grad_b = -2.0 * np.sum(y_d - y_hat) / m
grad_w = -2.0 * np.dot(y_d - y_hat, x_d) / m
# update param
b -= lr * grad_b
w -= lr * grad_w
b_history.append(b)
w_history.append(w)
loss_history.append(loss)
if i % 10000 == 0:
print("Step %i, w: %0.4f, b: %.4f, Loss: %.4f" % (i, w, b, loss))
end = time.time()
print("大约需要时间:", end - start)
# plot the figure
plt.contourf(x, y, Z, 50, alpha=0.5, cmap=plt.get_cmap('jet')) # 填充等高线
plt.plot([-188.4], [2.67], 'x', ms=12, mew=3, color="orange")
plt.plot(b_history, w_history, 'o-', ms=3, lw=1.5, color='black')
plt.xlim(-200, -100)
plt.ylim(-5, 5)
plt.xlabel(r'$b$')
plt.ylabel(r'$w$')
plt.title("线性回归")
plt.show()
# linear regression
b = -120
w = -4
lr = 1
iteration = 100000
b_history = [b]
w_history = [w]
lr_b = 0
lr_w = 0
import time
start = time.time()
for i in range(iteration):
b_grad = 0.0
w_grad = 0.0
for n in range(len(x_data)):
b_grad = b_grad - 2.0 * (y_data[n] - n - w * x_data[n]) * 1.0
w_grad = w_grad - 2.0 * (y_data[n] - n - w * x_data[n]) * x_data[n]
lr_b = lr_b + b_grad ** 2
lr_w = lr_w + w_grad ** 2
# update param
b -= lr / np.sqrt(lr_b) * b_grad
w -= lr / np.sqrt(lr_w) * w_grad
b_history.append(b)
w_history.append(w)
# plot the figure
plt.contourf(x, y, Z, 50, alpha=0.5, cmap=plt.get_cmap('jet')) # 填充等高线
plt.plot([-188.4], [2.67], 'x', ms=12, mew=3, color="orange")
plt.plot(b_history, w_history, 'o-', ms=3, lw=1.5, color='black')
plt.xlim(-200, -100)
plt.ylim(-5, 5)
plt.xlabel(r'$b$')
plt.ylabel(r'$w$')
plt.title("线性回归")
plt.show()阅读量:649
点赞量:0
收藏量:0