深入浅出RPC---2、序列化技术-灵析社区
 提笔写架构
提笔写架构RPC深入解析
上文说到RPC架构,那RPC底层涉及哪些技术呢,下面我们来详细解析下。
序列化技术
序列化流程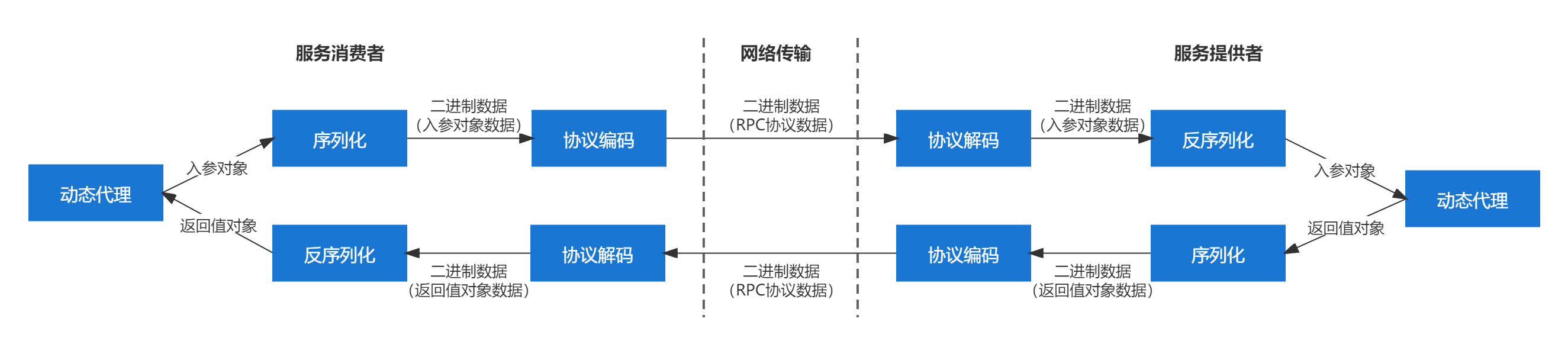
 序列化作用
序列化作用
在网络传输中,数据必须采用二进制形式, 所以在RPC调用过程中, 需要采用序列化技术,对入参对象和返 回值对象进行序列化与反序列化。
序列化处理要素
解析效率:序列化协议应该首要考虑的因素,像xml/json解析起来比较耗时,需要解析doom树,二进 制自定义协议解析起来效率要快很多。
压缩率:同样一个对象,xml/json传输起来有大量的标签冗余信息,信息有效性低,二进制自定义协议 占用的空间相对来说会小很多。
扩展性与兼容性:是否能够利于信息的扩展,并且增加字段后旧版客户端是否需要强制升级,这都是需 要考虑的问题,在自定义二进制协议时候,要做好充分考虑设计。
可读性与可调试性:xml/json的可读性会比二进制协议好很多,并且通过网络抓包是可以直接读取,二 进制则需要反序列化才能查看其内容。
跨语言:有些序列化协议是与开发语言紧密相关的,例如dubbo的Hessian序列化协议就只能支持Java 的RPC调用。
通用性:xml/json非常通用,都有很好的第三方解析库,各个语言解析起来都十分方便,二进制数据的 处理方面也有Protobuf和Hessian等插件,在做设计的时候尽量做到较好的通用性。
序列化方式
自定义的二进制协议来实现序列化:
下面以User对象例举讲解:
User对象:
package com.test;
public class User {
/**
* 用户编号
*/
private String userNo = "0001";
/**
* 用户名称
*/
private String name = "test";
}包体的数据组成:
业务指令为0x00000001占1个字节,类的包名com.test占10个字节, 类名User占4个字节; 属性UserNo名称占6个字节,属性类型string占2个字节表示,属性值为0001占4个字节; 属性name名称占4个字节,属性类型string占2个字节表示,属性值为zhangsan占8个字节; 包体共计占有1+10+4+6+2+4+4+2+8 = 41字节。
包头的数据组成:
版本号v1.0占4个字节,消息包体实际长度为41占4个字节表示,序列号0001占4个字节,校验码32位表示占4 个字节。
包头共计占有4+4+4+4 = 16字节。
包尾的数据组成: 通过回车符标记结束\r\n,占用1个字节。
整个包的序列化二进制字节流共41+16+1 = 58字节。这里讲解的是整个序列化的处理思路, 在实际的序列化处理中还要考虑更多细节,比如说方法和属性的区分,方法权限的标记,嵌套类型的处理等等;
JDK原生序列化
public static void main(String[] args) throws IOException, ClassNotFoundException {
String basePath = "D:/TestCode";
FileOutputStream fos = new FileOutputStream(basePath + "tradeUser.clazz");
TradeUser tradeUser = new TradeUser();
tradeUser.setName("Mirson");
ObjectOutputStream oos = new ObjectOutputStream(fos);
oos.writeObject(tradeUser);
oos.flush();
oos.close();
FileInputStream fis = new FileInputStream(basePath + "tradeUser.clazz");
ObjectInputStream ois = new ObjectInputStream(fis);
TradeUser deStudent = (TradeUser) ois.readObject();
ois.close();
System.out.println(deStudent);
}
在Java中,序列化必须要实现java.io.Serializable接口。
通过ObjectOutputStream和ObjectInputStream对象进行序列化及反序列化操作。
虚拟机是否允许反序列化,不仅取决于类路径和功能代码是否一致,一个非常重要的一点是两个类的 序列化 ID 是否一致(也就是在代码中定义的序列ID private static final long serialVersionUID)
序列化并不会保存静态变量。
要想将父类对象也序列化,就需要让父类也实现Serializable 接口。
Transient关键字的作用是控制变量的序列化,在变量声明前加上该关键字,可以阻止该变量被序列 化到文件中,在被反序列化后,transient变量的值被设为初始值,如基本类型 int为 0,封装对象型 Integer则为null。
服务器端给客户端发送序列化对象数据并非加密的,如果对象中有一些敏感数据比如密码等,那么在 对密码字段序列化之前,最好做加密处理,这样可以一定程度保证序列化对象的数据安全。
JSON序列化
一般在HTTP协议的RPC框架通信中,会选择JSON方式。
优点:JSON具有较好的扩展性、可读性和通用性。
缺点:JSON序列化占用空间开销较大,没有JAVA的强类型区分,需要通过反射解决,解析效率和压缩率都 较差。
如果对并发和性能要求较高,或者是传输数据量较大的场景,不建议采用JSON序列化方式。
Hessian2序列化
Hessian 是一个动态类型,二进制序列化,并且支持跨语言特性的序列化框架。 Hessian 性能上要比 JDK、JSON 序列化高效很多,并且生成的字节数也更小。有非常好的兼容性和稳定 性,所以 Hessian 更加适合作为 RPC 框架远程通信的序列化协议。
代码示例:
TradeUser tradeUser = new TradeUser();
tradeUser.setName("Mirson");
//tradeUser对象序列化处理
ByteArrayOutputStream bos = new ByteArrayOutputStream();
Hessian2Output output = new Hessian2Output(bos);
output.writeObject(tradeUser);
output.flushBuffer();
byte[] data = bos.toByteArray();
bos.close();
//tradeUser对象反序列化处理
ByteArrayInputStream bis = new ByteArrayInputStream(data);
Hessian2Input input = new Hessian2Input(bis);
TradeUser deTradeUser = (TradeUser) input.readObject();
input.close();
System.out.println(deTradeUser);
Hessian自身也存在一些缺陷,大家在使用过程中要注意:
对Linked系列对象不支持,比如LinkedHashMap、LinkedHashSet 等,但可以通过CollectionSerializer类修复。
Locale 类不支持,可以通过扩展 ContextSerializerFactory类修复。
Byte/Short在反序列化的时候会转成 Integer。
Protobuf序列化
Protobuf 是 Google 推出的开源序列库,它是一种轻便、高效的结构化数据存储格式,可以用于结构化 数据序列化,支持 Java、Python、C++、Go 等多种语言。
Protobuf 使用的时候需要定义 IDL(Interface description language),然后使用不同语言的 IDL 编译 器,生成序列化工具类,它具备以下优点:
压缩比高,体积小,序列化后体积相比 JSON、Hessian 小很多;
IDL能清晰地描述语义,可以帮助并保证应用程序之间的类型不会丢失,无需类似 XML 解析器;
序列化反序列化速度很快,不需要通过反射获取类型;
消息格式的扩展、升级和兼容性都不错,可以做到向后兼容。
代码示例:
Protobuf脚本定义:
// 定义Proto版本
syntax = "proto3";
// 是否允许生成多个JAVA文件
option java_multiple_files = false;
// 生成的包路径
option java_package = "com.itcast.bulls.stock.struct.netty.trade";
// 生成的JAVA类名
option java_outer_classname = "TradeUserProto";
// 预警通知消息体
message TradeUser {
/**
* 用户ID
*/
int64 userId = 1 ;
/**
* 用户名称
*/
string userName = 2 ;
}
代码操作:
// 创建TradeUser的Protobuf对象
TradeUserProto.TradeUser.Builder builder = TradeUserProto.TradeUser.newBuilder(); builder.setUserId(101);
builder.setUserName("Mirson");
//将TradeUser做序列化处理
TradeUserProto.TradeUser msg = builder.build();
byte[] data = msg.toByteArray();
//反序列化处理, 将刚才序列化的byte数组转化为TradeUser对象
TradeUserProto.TradeUser deTradeUser = TradeUserProto.TradeUser.parseFrom(data); System.out.println(deTradeUser);
阅读量:2108
点赞量:0
收藏量:0