深入浅出消息队列---8、Kafka消息可靠性-灵析社区
 提笔写架构
提笔写架构Kafka消息可靠性
第一种情况
消费端消息丢失
场景描述:
位移提交:对于Kafka中的分区而言,它的每条消息都有唯一的offset,用来表示消息在分区中的位置。对于消费者而言,它也有一个offset的概念,消费者使用offset来表示消费到分区中某个消息所在的位置。
单词"offset"可以编译为"偏移量",也可以翻译为"位移",在很多的中文资料中都会交叉使用"偏移量"和"位移"这两个词,对于消息在分区中的位置,我们将offset称之为"偏移量";对于消费者消费到的位置,将offset称为"位移",有时候也会更明确地称之为"消费位移"("偏移量"是在讲分区存储层面的内容,"位移"是在讲消费层面的内容)当然对于一条消息而言,它的偏移量和消费者消费它时的消费位移是相等的。
当每一次调用poll()方法时,它返回的是还没有消费过的消息集(当然这个前提是消息以及存储在Kafka中了,并且暂不考虑异常情况的发生),要做到这一点,就需要记录上一次消费时的消费位移。并且这个消费位移必须做持久化保存,而不是单单保存在内存中,否则消费者重启之后就无法知晓之前的消费位移。
消费位移存储在Kafka内部的主题__consumer_offsets中。这里把将消费位移存储起来的动作称之为"提交",消费者在消费完消息之后需要执行消费位移的提交。默认情况下Kafka的消费位移提交是自动提交,这个由消费者客户端参数enable.auto.commit配置,默认值为true。当然这个默认的自动提交并不是每消费一条消息就提交一次,而是定期提交,这个定期的周期时间由客户端参数auto.commit.interval.ms配置,默认值为5秒。自动位移提交的动作是在poll()方法的逻辑里面完成的,在每次真正向服务端发起拉取请求之前会检查是否可以进行位移提交,如果可以,那么就会提交上一次轮询的位移。
自动位移提交带来为问题:
1、重复消费
2、消息丢失
问题描述
重复消费原理如下图所示:
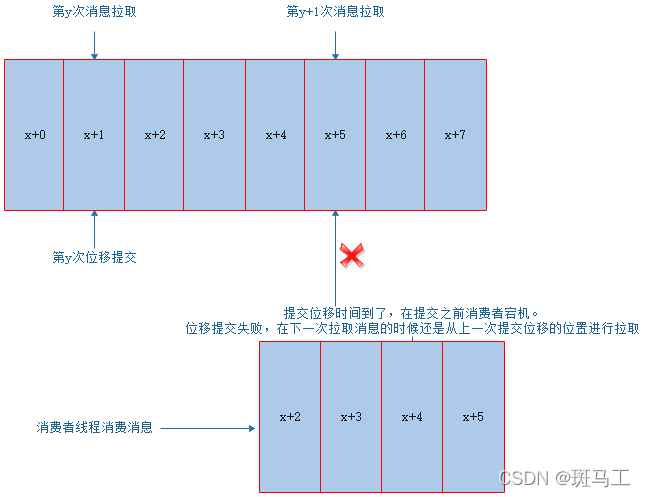
消息丢失如下图所示:

解决方案
解决方案:将自动位移提交更改为手动位移提交
注意:
1、在单独使用Kafka的java客户端将位移提交的模式更改为手动位移提交,那么我们就需要显示的调用consumer的方法完成位移提交。
// 通过Kafka的方式消费消息,如果将位移提交更改为手动位移提交。那么我们就需要主动调用consumer的方法完成位移提交
private static void consumerFromKafka() {
// 创建属性集合,设置初始化参数
Properties properties = new Properties();
properties.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.put("bootstrap.servers", "192.168.23.131:9092");
properties.put("group.id", "dd.demo");
properties.put("enable.auto.commit" , "false") ;
// 创建KafkaConsumer对象
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);
consumer.subscribe(Collections.singletonList("dd"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> record : records) {
System.out.println(record.value());
}
// consumer.commitSync(); // 进行同步位移提交,会阻塞当前线程
consumer.commitAsync(new OffsetCommitCallback(){
@Override
public void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets, Exception exception) {
if (exception == null) {
System.out.println(offsets);
} else {
LOGGER.error("fail to commit offsets {}", offsets, exception);
}
}
});
}
}
2、 在使用的是spring boot和Kafka进行整合,当我们将spring.kafka.consumer.enable-auto-commit的值设置为false以后,只有在特定的提交模式下我们可以手动进行提交。
在一些提交模式下由spring根据约定的条件控制提交。
常见的提交模式是在ContainerProperties.AckMode这个枚举类中定义。AckMode针对ENABLE_AUTO_COMMIT_CONFIG=false时生效,有以下几种:
- RECORD : 每处理一条commit一次
- BATCH : 每次poll的时候批量提交一次,频率取决于每次poll的调用频率
- TIME : 每次间隔ackTime的时间去commit
- COUNT : 累积达到ackCount次的ack去commit
- COUNT_TIME: ackTime或ackCount哪个条件先满足,就commit
- MANUAL : listener负责ack,但是背后也是批量上去
- MANUAL_IMMEDIATE : listner负责ack,每调用一次,就立即commit
spring配置如下:
# kafka配置
spring:
kafka:
consumer:
bootstrap-servers: 192.168.23.131:9092
enable-auto-commit: false # 设置手动位移提交
listener:
ack-mode: manual_immediate
代码实现:
@KafkaListener(topics = "dd" , groupId = "dd.demo")
public void consumerHandler(String msg , KafkaConsumer consumer) {
LOGGER.info("consumer topic is : {} , msg is ----> {} " , "itheima"
, msg);
// consumer.commitSync(); // 同步位移提交
consumer.commitAsync((offsets , e) -> {
if(e == null){
LOGGER.info("位移提交成功....");
}else {
Set<Map.Entry<TopicPartition, OffsetAndMetadata>> entries =offsets.entrySet();
for(Map.Entry<TopicPartition , OffsetAndMetadata> entry :entries) {
TopicPartition topicPartition = entry.getKey();
OffsetAndMetadata offsetAndMetadata = entry.getValue();
LOGGER.info("位移提交失败....topicPartition is {} ,offsets is {} " , topicPartition.partition() ,offsetAndMetadata.offset());
}
}
});
}
第二种情况
生产者将消息发送到Broker中以后,消息还没有被及时消费,此时Broker宕机了,这样就会导致消息丢失。
问题描述
Kafka消息的发送流程:
在消息发送的过程中,涉及到了两个线程——main线程和Sender线程,以及一个线程共享变量——RecordAccumulator。main线程将消息发送给RecordAccumulator,Sender线程会根据指定的条件,不断从RecordAccumulator中拉取消息发送到Kafka broker。如下图所示:
Sender线程拉取消息的条件:
- 缓冲区大小达到一定的阈值(默认是16384byte),可以通过spring.kafka.producer.batch-size进行设定
- 缓冲区等待的时间达到设置的阈值(默认是0), 可以通过linger.ms属性进行设定
发送消息的三种方式:1、发后即忘 2、同步消息发送 3、异步消息发送
- 发后即忘
只管往kafka发送消息(消息只发送到缓冲区)而并不关心消息是否正确到达。正常情况没什么问题,不过有些时候(比如不可重试异常)会造成消息的丢失。
这种发送方式性能最高,可靠性最差。如下所示:
// 演示消息发送: 发送即忘
public static void sendMessageMethod01() {
for(int x = 0 ; x < 5 ; x++) {
String msg = "Kakfa环境测试...." + x ;
kafkaTemplate.send("itheima" , msg) ; // 发后即
忘
LOGGER.info("send msg success ---> {} " , msg);
}
}
- 同步消息发送
其实kafkaTemplate.send方法并不是返回void,而是ListenableFuture<SendResult<K, V>>,该类继承了jdk concurrent包的Future。如下:
@Override
public ListenableFuture<SendResult<K, V>> send(String topic, @Nullable V
data) {
ProducerRecord<K, V> producerRecord = new ProducerRecord<>(topic,
data);
return doSend(producerRecord);
} 12345
要实现同步发送的,可以利用返回的ListenableFuture实现,如下:
// 演示消息发送: 同步发送
public static void sendMessageMethod02() throws ExecutionException,
InterruptedException {
for(int x = 0 ; x < 5 ; x++) {
String msg = "Kakfa环境测试...." + x ;
kafkaTemplate.send("itheima" , msg).get() ; // 同步消息发
送
LOGGER.info("send msg success ---> {} " , msg);
}
}
实际上send()方法本身就是异步的,send()方法返回的Future对象可以使调用方稍后获得发送的结果。在执行send()方法之后直接链式调用了get()方法可以阻塞等待Kafka的响应,直到消息发送成功,或者发生异常。如果发生异常,那么就需要捕获异常并交由外层逻辑处理。这种方式性能最差,可靠性较好。
- 异步发送
在send方法里指定一个Callback的回调函数,Kafka在返回响应时调用该函数来实现异步的发送确认。异步发送方式的示例如下:
// 演示消息发送: 异步发送
public static void sendMessageMethod03() throws ExecutionException,
InterruptedException {
for(int x = 0 ; x < 5 ; x++) {
// Kafka消息的异步发送
String msg = "Kakfa环境测试...." + x ;
kafkaTemplate.send("itheima" , msg).addCallback((obj) -> {
LOGGER.info("send msg to kafka broker success ---> {} " ,
((SendResult)obj).getProducerRecord().value());
} , (t) -> {
t.printStackTrace();
});
LOGGER.info("send msg to local cache success ---> {} " , msg);
}
}
这种方式的特点:性能较好,可靠性也有保障
解决方案
针对上述情况所产生的消息丢失,可以的解决方案有如下几种:
- 给topic设置replication.factor参数大于1,要求每个partition必须最少有两个副本
- 搭建Kafka集群,让各个分区副本均衡的分配到不同的broker上
- 在producer端设置acks=all,要求每条数据写入replicas后,才认为写入成功:
- ack=0, 生产者在成功写入消息之前不会等待任何来自服务器的响应。如果出现问题生产者是感知不到的,消息就丢失了。不过因为生产者不需要等待服务器响应,所以它可以以网络能够支持的最大速度发送消息,从而达到很高的吞吐量。
- ack=1,默认值为1,只要集群的首领节点收到消息,生产者就会收到一个来自服务器的成功响应。如果消息无法达到首领节点(比如首领节点崩溃,新的首领还没有被选举出来),生产者会收到一个错误响应,为了避免数据丢失,生产者会重发消息(Kafka生产者内部机制)。但是,这样还有可能会导致数据丢失,如果收到写成功通知,此时首领节点还没来
的及同步数据到follower节点,首领节点崩溃,就会导致数据丢失。 - ack=-1/all, 只有当所有参与复制的节点都收到消息时,生产者会收到一个来自服务器的成功响应,这种模式是最安全的,它可以保证不止一个服务器收到消息。
当生产者发送消息完毕以后,没有收到Broker返回的ack,此时就会触发重试机制或者抛出异常。我们可以通过retries参数设置重试次数(spring boot和Kafka整合默认的重试次数为0),发送客户端会进行重试直到broker返回ack。
阅读量:2102
点赞量:0
收藏量:0