Pytorch10天入门-day09-模型微调-灵析社区
 清晨我上码
清晨我上码模型微调(fine-tune)-迁移学习
- torchvision微调
- timm微调
- 半精度训练
- 起源:
- 1、随着深度学习的发展,模型的参数越来越大,许多开源模型都是在较大数据集上进行训练的,比如Imagenet-1k,Imagenet-11k等
- 2、如果数据集可能只有几千张,训练几千万参数的大模型,过拟合无法避免
- 3、如果我们想从零开始训练一个大模型,那么我们的解决办法是收集更多的数据。然而,收集和标注数据会花费大量的时间和资⾦,成本无法承受
- 解决方案:
- 应用迁移学习(transfer learning),将从源数据集学到的知识迁移到目标数据集上
- 比如:ImageNet数据集的图像大多跟椅子无关,但在该数据集上训练的模型可以抽取较通用的图像特征,从而能够帮助识别边缘、纹理、形状和物体组成
- 模型微调(finetune):就是先找到一个同类的别人训练好的模型,基于已经训练好的模型换成自己的数据,通过训练调整一下参数
不同数据集下使用微调:
- 数据集1 - 数据量少,但数据相似度非常高 - 在这种情况下,我们所做的只是修改最后几层或最终的softmax图层的输出类别。
- 数据集2 - 数据量少,数据相似度低 - 在这种情况下,我们可以冻结预训练模型的初始层(比如k层),并再次训练剩余的(n-k)层。由于新数据集的相似度较低,因此根据新数据集对较高层进行重新训练具有重要意义。
- 数据集3 - 数据量大,数据相似度低 - 在这种情况下,由于我们有一个大的数据集,我们的神经网络训练将会很有效。但是,由于我们的数据与用于训练我们的预训练模型的数据相比有很大不同。使用预训练模型进行的预测不会有效。因此,最好根据你的数据从头开始训练神经网络(Training from scatch)
- 数据集4 - 数据量大,数据相似度高 - 这是理想情况。在这种情况下,预训练模型应该是最有效的。使用模型的最好方法是保留模型的体系结构和模型的初始权重。然后,我们可以使用在预先训练的模型中的权重来重新训练该模型。
微调的是什么?
- 换数据源
- 针对K层进行重新训练
- K层的权重&shape调整
1、模型微调(fine-tune)一般流程:
- 1、在源数据集(如ImageNet数据集)上预训练一个神经网络模型,即源模型
- 2、创建一个新的神经网络模型,即目标模型,它复制了源模型上除了输出层外的所有模型设计及其参数
- 3、为目标模型添加一个输出⼤小为⽬标数据集类别个数的输出层,并随机初始化该层的模型参数
- 4、在目标数据集上训练目标模型。我们将从头训练输出层,而其余层的参数都是基于源模型的参数微调得到的

2、torchvision微调
2.1 实例化Model
import torchvision.modelsas models
resnet34= models.resnet34(pretrained=True)pretrained参数说明:
- 1、通过True或者False来决定是否使用预训练好的权重,在默认状态下pretrained = False,意味着我们不使用预训练得到的权重
- 2、当pretrained = True,意味着我们将使用在一些数据集上预训练得到的权重
- 注意:如果中途强行停止下载的话,一定要去对应路径下将权重文件删除干净,否则会报错。
2.2 训练特定层
如果我们正在提取特征并且只想为新初始化的层计算梯度,其他参数不进行改变。那我们就需要通过设置requires_grad = False来冻结部分层
def set_parameter_requires_grad(model, feature_extracting):
if feature_extracting:
for paramin model.parameters():
param.requires_grad=False2.3 实例
- 使用resnet34为例的将1000类改为10类,但是仅改变最后一层的模型参数
- 我们先冻结模型参数的梯度,再对模型输出部分的全连接层进行修改
import torch
import torch.nn.functional as F
import torch.nn as nn
from torch.optim.lr_scheduler import LambdaLR
from torch.optim.lr_scheduler import StepLR
import torchvision
from torch.utils.data import Dataset, DataLoader
from torchvision.transforms import transforms
from torch.utils.tensorboard import SummaryWriter
import numpy as np
import torchvision.models as models
from torchinfo import summary#超参数定义
# 批次的大小
batch_size = 16 #可选32、64、128
# 优化器的学习率
lr = 1e-4
#运行epoch
max_epochs = 2
# 方案二:使用“device”,后续对要使用GPU的变量用.to(device)即可
device = torch.device("cuda:1" if torch.cuda.is_available() else "cpu")#超参数定义
# 批次的大小
batch_size = 16 #可选32、64、128
# 优化器的学习率
lr = 1e-4
#运行epoch
max_epochs = 2
# 方案二:使用“device”,后续对要使用GPU的变量用.to(device)即可
device = torch.device("cuda:1" if torch.cuda.is_available() else "cpu")# 数据读取
#cifar10数据集为例给出构建Dataset类的方式
from torchvision import datasets
#“data_transform”可以对图像进行一定的变换,如翻转、裁剪、归一化等操作,可自己定义
data_transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))
])
train_cifar_dataset = datasets.CIFAR10('cifar10',train=True, download=False,transform=data_transform)
test_cifar_dataset = datasets.CIFAR10('cifar10',train=False, download=False,transform=data_transform)
#构建好Dataset后,就可以使用DataLoader来按批次读入数据了
train_loader = torch.utils.data.DataLoader(train_cifar_dataset,
batch_size=batch_size, num_workers=4,
shuffle=True, drop_last=True)
test_loader = torch.utils.data.DataLoader(test_cifar_dataset,
batch_size=batch_size, num_workers=4,
shuffle=False)# 下载预训练模型 restnet34
resnet34 = models.resnet34(pretrained=True)
print(resnet34)#查看模型结构
summary(resnet34, (1, 3, 224, 224))#检测 模型准确率
def cal_predict_correct(model):
test_total_correct = 0
for iter,(images,labels) in enumerate(test_loader):
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
test_total_correct += (outputs.argmax(1) == labels).sum().item()
# print("test_total_correct: "+ str(test_total_correct))
return test_total_correcttotal_correct = cal_predict_correct(resnet34)
print("test_total_correct: "+ str(test_total_correct / 10000))test_total_correct: 0.1
#微调模型 resnet34
def set_parameter_requires_grad(model, feature_extracting):
if feature_extracting:
for param in model.parameters():
param.requires_grad = False
# 冻结参数的梯度
feature_extract = True
new_model = resnet34
set_parameter_requires_grad(new_model, feature_extract)
# 修改模型
#训练过程中,model仍会进行梯度回传,但是参数更新则只会发生在fc层
num_ftrs = new_model.fc.in_features
new_model.fc = nn.Linear(in_features=num_ftrs, out_features=10, bias=True)
summary(new_model, (1, 3, 224, 224))#训练&验证
Resnet34_new = new_model.to(device)
# 定义损失函数和优化器
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
# 损失函数:自定义损失函数
criterion = nn.CrossEntropyLoss()
# 优化器
optimizer = torch.optim.Adam(Resnet50_new.parameters(), lr=lr)
epoch = max_epochs
total_step = len(train_loader)
train_all_loss = []
test_all_loss = []
for i in range(epoch):
Resnet34_new.train()
train_total_loss = 0
train_total_num = 0
train_total_correct = 0
for iter, (images,labels) in enumerate(train_loader):
images = images.to(device)
labels = labels.to(device)
outputs = Resnet34_new(images)
loss = criterion(outputs,labels)
train_total_correct += (outputs.argmax(1) == labels).sum().item()
#backword
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_total_num += labels.shape[0]
train_total_loss += loss.item()
print("Epoch [{}/{}], Iter [{}/{}], train_loss:{:4f}".format(i+1,epoch,iter+1,total_step,loss.item()/labels.shape[0]))
Resnet34_new.eval()
test_total_loss = 0
test_total_correct = 0
test_total_num = 0
for iter,(images,labels) in enumerate(test_loader):
images = images.to(device)
labels = labels.to(device)
outputs = Resnet34_new(images)
loss = criterion(outputs,labels)
test_total_correct += (outputs.argmax(1) == labels).sum().item()
test_total_loss += loss.item()
test_total_num += labels.shape[0]
print("Epoch [{}/{}], train_loss:{:.4f}, train_acc:{:.4f}%, test_loss:{:.4f}, test_acc:{:.4f}%".format(
i+1, epoch, train_total_loss / train_total_num, train_total_correct / train_total_num * 100, test_total_loss / test_total_num, test_total_correct / test_total_num * 100
))
train_all_loss.append(np.round(train_total_loss / train_total_num,4))
test_all_loss.append(np.round(test_total_loss / test_total_num,4))total_correct = cal_predict_correct(Resnet34_new)
print("test_total_correct: "+ str(test_total_correct / 10000))test_total_correct: 0.1
3、timm微调
- 安装:pip3 install timm
3.1、查看预训练模型¶
import timm
from torchinfo import summary
avail_pretrained_models = timm.list_models(pretrained=True)
len(avail_pretrained_models)# 模型列表
avail_pretrained_models3.1.1、查看模型参数
model = timm.create_model('resnet18',pretrained=True)
model.default_cfg{'url': 'https://download.pytorch.org/models/resnet18-5c106cde.pth',
'num_classes': 1000,
'input_size': (3, 224, 224),
'pool_size': (7, 7),
'crop_pct': 0.875,
'interpolation': 'bilinear',
'mean': (0.485, 0.456, 0.406),
'std': (0.229, 0.224, 0.225),
'first_conv': 'conv1',
'classifier': 'fc',
'architecture': 'resnet18'}3.2、修改预训练模型
# 测试模型
x = torch.randn(1,3,224,224)
output = model(x)
output.shapetorch.Size([1, 1000])
3.2.1、查看某一层模型参数(以第一层卷积为例)
list(dict(model.named_children())['conv1'].parameters())[Parameter containing:
tensor([[[[-1.0419e-02, -6.1356e-03, -1.8098e-03, ..., 5.6615e-02,
1.7083e-02, -1.2694e-02],
[ 1.1083e-02, 9.5276e-03, -1.0993e-01, ..., -2.7124e-01,
-1.2907e-01, 3.7424e-03],
[-6.9434e-03, 5.9089e-02, 2.9548e-01, ..., 5.1972e-01,
2.5632e-01, 6.3573e-02],
...,
[-2.7535e-02, 1.6045e-02, 7.2595e-02, ..., -3.3285e-01,
-4.2058e-01, -2.5781e-01],
[ 3.0613e-02, 4.0960e-02, 6.2850e-02, ..., 4.1384e-01,
3.9359e-01, 1.6606e-01],
[-1.3736e-02, -3.6746e-03, -2.4084e-02, ..., -1.5070e-01,
-8.2230e-02, -5.7828e-03]],
[[-1.1397e-02, -2.6619e-02, -3.4641e-02, ..., 3.2521e-02,
6.6221e-04, -2.5743e-02],
[ 4.5687e-02, 3.3603e-02, -1.0453e-01, ..., -3.1253e-01,
-1.6051e-01, -1.2826e-03],
[-8.3730e-04, 9.8420e-02, 4.0210e-01, ..., 7.0789e-01,
3.6887e-01, 1.2455e-01],#微调
#修改模型(将1000类改为10类输出)
#改变输入通道数(比如我们传入的图片是单通道的,但是模型需要的是三通道图片)
#我们可以通过添加in_chans=1来改变
model = timm.create_model('resnet18',num_classes=10,pretrained=True,in_chans=1)
x = torch.randn(1,1,224,224)
output = model(x)
output.shape#模型保存
torch.save(model.state_dict(),'./checkpoint/timm_model.pth')
model.load_state_dict(torch.load('./checkpoint/timm_model.pth'))4、半精度训练
问题:
- GPU的性能主要分为两部分:算力和显存。
- 前者决定了显卡计算的速度,后者则决定了显卡可以同时放入多少数据用于计算
- 在可以使用的显存数量一定的情况下,每次训练能够加载的数据更多(也就是batch size更大),则也可以提高训练效率
- 定义:
- PyTorch默认的浮点数存储方式用的是torch.float32,小数点后位数更多固然能保证数据的精确性
- 但绝大多数场景其实并不需要这么精确,只保留一半的信息也不会影响结果,也就是使用torch.float16格式。由于数位减了一半,因此被称为“半精度”
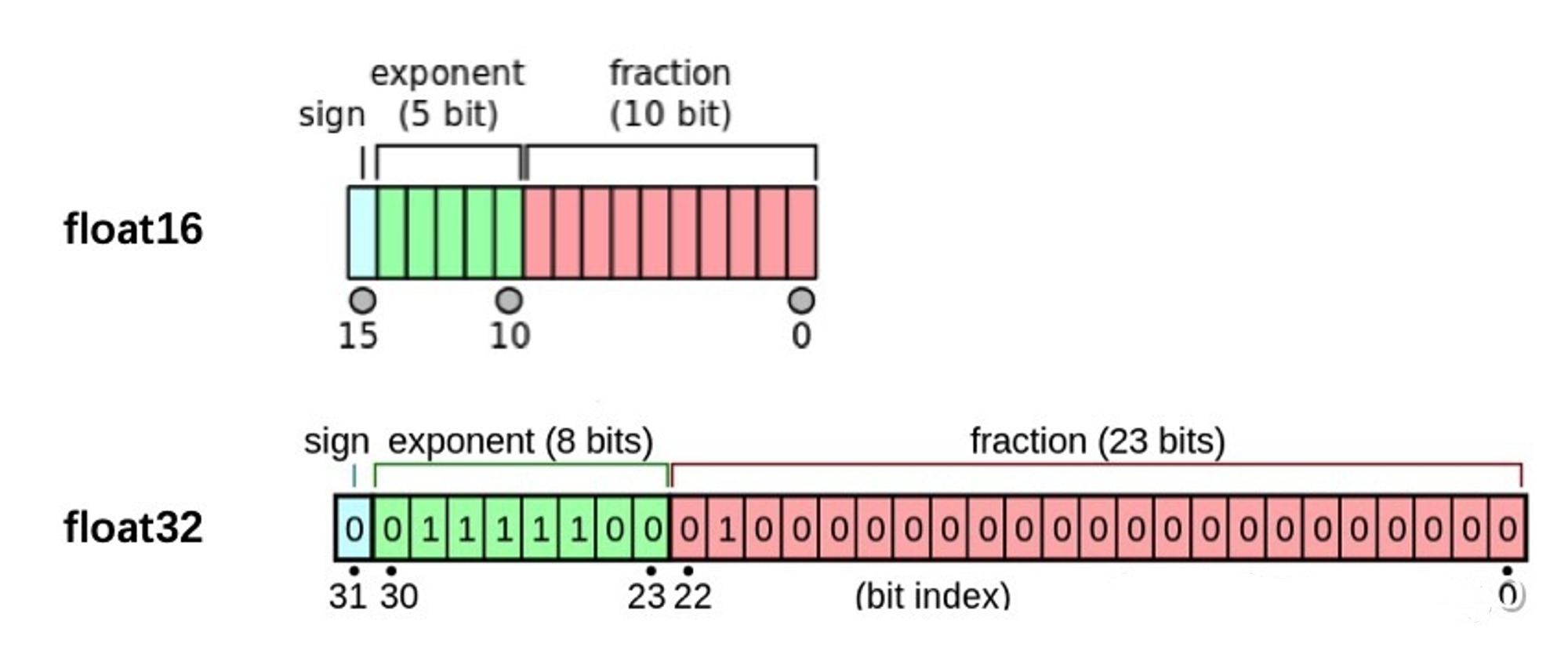
显然半精度能够减少显存占用,使得显卡可以同时加载更多数据进行计算
4.1、半精度训练的设置
- 1、引入 from torch.cuda.amp import autocast
- 2、forward函数指定 autocast 装饰器
- 3、训练过程: 只需在将数据输入模型及其之后的部分放入“with autocast():“
- 4、半精度训练主要适用于数据本身的size比较大(比如说3D图像、视频等)
4.2、引入
from torch.cuda.amp import autocast
# forward指定装饰器@autocast()
def forward(self, x):
...return x# 训练过程中:指定with autocastfor xin train_loader:
x= x.cuda()
with autocast():
output= model(x)
...4.3、半精度训练案例
from torch.cuda.amp import autocast
# 半精度模型
class DemoModel(nn.Module):
def __init__(self):
super(DemoModel, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
@autocast()
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x#训练&验证
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
half_model = DemoModel().to(device)
# 损失函数:自定义损失函数
criterion = nn.CrossEntropyLoss()
# 优化器
optimizer = torch.optim.Adam(Resnet50_new.parameters(), lr=lr)
epoch = max_epochs
total_step = len(train_loader)
train_all_loss = []
test_all_loss = []
for i in range(epoch):
half_model.train()
train_total_loss = 0
train_total_num = 0
train_total_correct = 0
for iter, (images,labels) in enumerate(train_loader):
images = images.to(device)
labels = labels.to(device)
with autocast():
outputs = half_model(images)
loss = criterion(outputs,labels)
train_total_correct += (outputs.argmax(1) == labels).sum().item()
#backword
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_total_num += labels.shape[0]
train_total_loss += loss.item()
print("Epoch [{}/{}], Iter [{}/{}], train_loss:{:4f}".format(i+1,epoch,iter+1,total_step,loss.item()/labels.shape[0]))
half_model.eval()
test_total_loss = 0
test_total_correct = 0
test_total_num = 0
for iter,(images,labels) in enumerate(test_loader):
images = images.to(device)
labels = labels.to(device)
with autocast():
outputs = half_model(images)
loss = criterion(outputs,labels)
test_total_correct += (outputs.argmax(1) == labels).sum().item()
test_total_loss += loss.item()
test_total_num += labels.shape[0]
print("Epoch [{}/{}], train_loss:{:.4f}, train_acc:{:.4f}%, test_loss:{:.4f}, test_acc:{:.4f}%".format(
i+1, epoch, train_total_loss / train_total_num, train_total_correct / train_total_num * 100, test_total_loss / test_total_num, test_total_correct / test_total_num * 100
))
train_all_loss.append(np.round(train_total_loss / train_total_num,4))
test_all_loss.append(np.round(test_total_loss / test_total_num,4))阅读量:2079
点赞量:0
收藏量:0