Pytorch10天入门-day06-复杂模型构建-灵析社区
 清晨我上码
清晨我上码1、PyTorch 复杂模型构建
- 1、模型截图
- 2、模型部件实现
- 3、模型组装
2、模型定义
2.1、Sequential
- 1、当模型的前向计算为简单串联各个层的计算时, Sequential 类可以通过更加简单的方式定义模型。
- 2、可以接收一个子模块的有序字典(OrderedDict) 或者一系列子模块作为参数来逐一添加 Module 的实例,模型的前向计算就是将这些实例按添加的顺序逐⼀计算
- 3、使用Sequential定义模型的好处在于简单、易读,同时使用Sequential定义的模型不需要再写forward
import torch.nn as nn
net = nn.Sequential(
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 10),
)
print(net)Sequential(
(0): Linear(in_features=784, out_features=256, bias=True)
(1): ReLU()
(2): Linear(in_features=256, out_features=10, bias=True)
)import collections
import torch.nn as nn
net2 = nn.Sequential(collections.OrderedDict([
('fc1', nn.Linear(784, 256)),
('relu1', nn.ReLU()),
('fc2', nn.Linear(256, 10))
]))
print(net2)Sequential(
(fc1): Linear(in_features=784, out_features=256, bias=True)
(relu1): ReLU()
(fc2): Linear(in_features=256, out_features=10, bias=True)
)2.2、ModuleList
- ModuleList 接收一个子模块(或层,需属于nn.Module类)的列表作为输入,然后也可以类似List那样进行append和extend操作
- nn.ModuleList 并没有定义一个网络,它只是将不同的模块储存在一起。ModuleList中元素的先后顺序并不代表其在网络中的真实位置顺序
net = nn.ModuleList([nn.Linear(784, 256), nn.ReLU()])
net.append(nn.Linear(256, 10)) # # 类似List的append操作
print(net[-1]) # 类似List的索引访问
print(net)Linear(in_features=256, out_features=10, bias=True)
ModuleList(
(0): Linear(in_features=784, out_features=256, bias=True)
(1): ReLU()
(2): Linear(in_features=256, out_features=10, bias=True)
)2.3、ModuleDict
- ModuleList 接收一个子模块(或层,需属于nn.Module类)的列表作为输入,然后也可以类似List那样进行append和extend操作
- 增加子模块或层的同时权重也会自动添加到网络中来
net = nn.ModuleDict({
'linear': nn.Linear(784, 256),
'act': nn.ReLU(),
})
net['output'] = nn.Linear(256, 10) # 添加
print(net['linear']) # 访问
print(net.output)
print(net)net = nn.ModuleDict({
'linear': nn.Linear(784, 256),
'act': nn.ReLU(),
})
net['output'] = nn.Linear(256, 10) # 添加
print(net['linear']) # 访问
print(net.output)
print(net)3、手搓Restnet50
3.1、Restnet50
resnet 在imageNet竞赛中分类任务第一名、目标检测第一名,获得COCO数据集中目标检测第一名,图像分割第一名。
3.2、手搓思路
resnet50讲解,网络的输入照片大小是224x224的经过conv1,conv2,conv3,conv4,conv5最后在平均池化,全连接层。由于中间有重复利用的模块,所以我们需要将它们写成一个类,用来重复调用即可
3.3、resetnet核心要点:
- 1、提出residual模块(残差)
- 2、使用Batch Normalization加速训练(均值为0,方差为1)


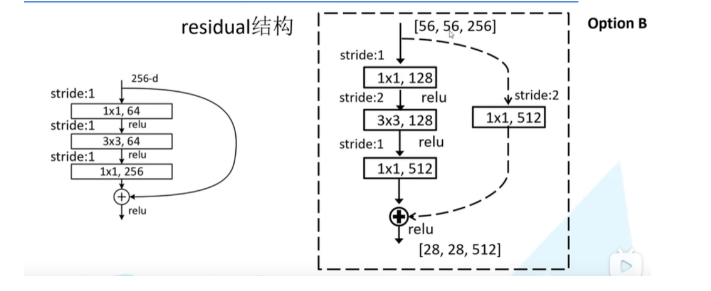
3.4 模型结构解析(restnet50)
- 1、conv1,stride=2,kernel_size=7,out_chnnels=64
- 2、conv2_x
- 2.1、 max_pool:kernel_size=3, stride=2
- 2.2、 conv_01:stride=1,kernel_size=1,out_chnnels=64
- 2.3、 conv_02:stride=2,kernel_size=3,out_chnnels=64
- 2.4、 conv_03:stride=1,kernel_size=1,out_chnnels=256
- 2.5、 layers(conv_01+conv_02+conv_03)*3
- 3、conv3_x
- 3.1、conv_01:stride=1,kernel_size=1,out_chnnels=128
- 3.2、conv_02:stride=2,kernel_size=3,out_chnnels=128
- 3.3、conv_03:stride=1,kernel_size=1,out_chnnels=512
- 3.4、residual:stride=2,kernel_size=1,out_chnnels=512
- 3.5、layers(conv_01+conv_02+conv_03)*4
- 4、conv4_x
- 4.1、conv_01:stride=1,kernel_size=1,out_chnnels=256
- 4.2、conv_02:stride=2,kernel_size=3,out_chnnels=256
- 4.3、conv_03:stride=1,kernel_size=1,out_chnnels=1024
- 4.4、residual:stride=2,kernel_size=1,out_chnnels=1024
- 4.5、layers(conv_01+conv_02+conv_03)*6
- 5、conv5_x
- 5.1、conv_01:stride=1,kernel_size=1,out_chnnels=512
- 5.2、conv_02:stride=2,kernel_size=3,out_chnnels=512
- 5.3、conv_03:stride=1,kernel_size=1,out_chnnels=2048
- 5.4、residual:stride=2,kernel_size=1,out_chnnels=2048
- 5.5、layers(conv_01+conv_02+conv_03)*3
- 6、fc
- 6.1、AdaptiveAvgPool2d:output=(1,1)
- 6.2、flatten:(x, 1)
- 6.3、fc:linear(512 * 4,num_class)
import torch.nn as nn
import torch
class Block(nn.Module):
def __init__(self, in_channels, out_channels, stride=1, downsample=False):
super(Block, self).__init__()
out_channel_01, out_channel_02, out_channel_03 = out_channels
self.downsample = downsample
self.relu = nn.ReLU(inplace=True)
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels, out_channel_01, kernel_size=1, stride=1,bias=False),
nn.BatchNorm2d(out_channel_01),
nn.ReLU(inplace=True)
)
self.conv2 = nn.Sequential(
nn.Conv2d(out_channel_01, out_channel_02, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(out_channel_02),
nn.ReLU(inplace=True)
)
self.conv3 = nn.Sequential(
nn.Conv2d(out_channel_02, out_channel_03, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(out_channel_03),
)
if downsample:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channel_03, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channel_03)
)
def forward(self,x):
x_shortcut = x
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
if self.downsample:
x_shortcut = self.shortcut(x_shortcut)
x = x + x_shortcut
x = self.relu(x)
return xclass Resnet50(nn.Module):
def __init__(self):
super(Resnet50,self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64),
nn.ReLU(),
)
Layers = [3, 4, 6, 3]
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.conv2 = self._make_layer(64, (64, 64, 256), Layers[0],1)
self.conv3 = self._make_layer(256, (128, 128, 512), Layers[1], 2)
self.conv4 = self._make_layer(512, (256, 256, 1024), Layers[2], 2)
self.conv5 = self._make_layer(1024, (512, 512, 2048), Layers[3], 2)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Sequential(
nn.Linear(2048, 1000)
)
def forward(self, input):
x = self.conv1(input)
x = self.maxpool(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.conv5(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def _make_layer(self, in_channels, out_channels, blocks, stride=1):
layers = []
block_1 = Block(in_channels, out_channels, stride=stride, downsample=True)
layers.append(block_1)
for i in range(1, blocks):
layers.append(Block(out_channels[2], out_channels, stride=1, downsample=False))
return nn.Sequential(*layers)#打印网络结构
net = Resnet50()
x = torch.rand((10, 3, 224, 224))
for name,layer in net.named_children():
if name != "fc":
x = layer(x)
print(name, 'output shaoe:', x.shape)
else:
x = x.view(x.size(0), -1)
x = layer(x)
print(name, 'output shaoe:', x.shape)conv1 output shaoe: torch.Size([10, 64, 112, 112])
maxpool output shaoe: torch.Size([10, 64, 56, 56])
conv2 output shaoe: torch.Size([10, 256, 56, 56])
conv3 output shaoe: torch.Size([10, 512, 28, 28])
conv4 output shaoe: torch.Size([10, 1024, 14, 14])
conv5 output shaoe: torch.Size([10, 2048, 7, 7])
avgpool output shaoe: torch.Size([10, 2048, 1, 1])
fc output shaoe: torch.Size([10, 1000])#torchinfo 可视化网络结构
from torchinfo import summary
net = Resnet50()
summary(net,((10, 3, 224, 224)))==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
Resnet50 [10, 1000] --
├─Sequential: 1-1 [10, 64, 112, 112] --
│ └─Conv2d: 2-1 [10, 64, 112, 112] 9,472
│ └─BatchNorm2d: 2-2 [10, 64, 112, 112] 128
│ └─ReLU: 2-3 [10, 64, 112, 112] --
├─MaxPool2d: 1-2 [10, 64, 56, 56] --
├─Sequential: 1-3 [10, 256, 56, 56] --
│ └─Block: 2-4 [10, 256, 56, 56] --
│ │ └─Sequential: 3-1 [10, 64, 56, 56] 4,224
│ │ └─Sequential: 3-2 [10, 64, 56, 56] 36,992
│ │ └─Sequential: 3-3 [10, 256, 56, 56] 16,896
│ │ └─Sequential: 3-4 [10, 256, 56, 56] 16,896
│ │ └─ReLU: 3-5 [10, 256, 56, 56] --
│ └─Block: 2-5 [10, 256, 56, 56] --
│ │ └─Sequential: 3-6 [10, 64, 56, 56] 16,512
│ │ └─Sequential: 3-7 [10, 64, 56, 56] 36,992
│ │ └─Sequential: 3-8 [10, 256, 56, 56] 16,896
│ │ └─ReLU: 3-9 [10, 256, 56, 56] --
│ └─Block: 2-6 [10, 256, 56, 56] --
│ │ └─Sequential: 3-10 [10, 64, 56, 56] 16,512
│ │ └─Sequential: 3-11 [10, 64, 56, 56] 36,992
│ │ └─Sequential: 3-12 [10, 256, 56, 56] 16,896
│ │ └─ReLU: 3-13 [10, 256, 56, 56] --
├─Sequential: 1-4 [10, 512, 28, 28] --
│ └─Block: 2-7 [10, 512, 28, 28] --
│ │ └─Sequential: 3-14 [10, 128, 56, 56] 33,024
│ │ └─Sequential: 3-15 [10, 128, 28, 28] 147,712
│ │ └─Sequential: 3-16 [10, 512, 28, 28] 66,560
│ │ └─Sequential: 3-17 [10, 512, 28, 28] 132,096
│ │ └─ReLU: 3-18 [10, 512, 28, 28] --
│ └─Block: 2-8 [10, 512, 28, 28] --
│ │ └─Sequential: 3-19 [10, 128, 28, 28] 65,792
│ │ └─Sequential: 3-20 [10, 128, 28, 28] 147,712
│ │ └─Sequential: 3-21 [10, 512, 28, 28] 66,560
│ │ └─ReLU: 3-22 [10, 512, 28, 28] --
│ └─Block: 2-9 [10, 512, 28, 28] --
│ │ └─Sequential: 3-23 [10, 128, 28, 28] 65,792
│ │ └─Sequential: 3-24 [10, 128, 28, 28] 147,712
│ │ └─Sequential: 3-25 [10, 512, 28, 28] 66,560
│ │ └─ReLU: 3-26 [10, 512, 28, 28] --
│ └─Block: 2-10 [10, 512, 28, 28] --
│ │ └─Sequential: 3-27 [10, 128, 28, 28] 65,792
│ │ └─Sequential: 3-28 [10, 128, 28, 28] 147,712
│ │ └─Sequential: 3-29 [10, 512, 28, 28] 66,560
│ │ └─ReLU: 3-30 [10, 512, 28, 28] --
├─Sequential: 1-5 [10, 1024, 14, 14] --
│ └─Block: 2-11 [10, 1024, 14, 14] --
│ │ └─Sequential: 3-31 [10, 256, 28, 28] 131,584
│ │ └─Sequential: 3-32 [10, 256, 14, 14] 590,336
│ │ └─Sequential: 3-33 [10, 1024, 14, 14] 264,192
│ │ └─Sequential: 3-34 [10, 1024, 14, 14] 526,336
│ │ └─ReLU: 3-35 [10, 1024, 14, 14] --
│ └─Block: 2-12 [10, 1024, 14, 14] --
│ │ └─Sequential: 3-36 [10, 256, 14, 14] 262,656
│ │ └─Sequential: 3-37 [10, 256, 14, 14] 590,336
│ │ └─Sequential: 3-38 [10, 1024, 14, 14] 264,192
│ │ └─ReLU: 3-39 [10, 1024, 14, 14] --
│ └─Block: 2-13 [10, 1024, 14, 14] --
│ │ └─Sequential: 3-40 [10, 256, 14, 14] 262,656
│ │ └─Sequential: 3-41 [10, 256, 14, 14] 590,336
│ │ └─Sequential: 3-42 [10, 1024, 14, 14] 264,192
│ │ └─ReLU: 3-43 [10, 1024, 14, 14] --
│ └─Block: 2-14 [10, 1024, 14, 14] --
│ │ └─Sequential: 3-44 [10, 256, 14, 14] 262,656
│ │ └─Sequential: 3-45 [10, 256, 14, 14] 590,336
│ │ └─Sequential: 3-46 [10, 1024, 14, 14] 264,192
│ │ └─ReLU: 3-47 [10, 1024, 14, 14] --
│ └─Block: 2-15 [10, 1024, 14, 14] --
│ │ └─Sequential: 3-48 [10, 256, 14, 14] 262,656
│ │ └─Sequential: 3-49 [10, 256, 14, 14] 590,336
│ │ └─Sequential: 3-50 [10, 1024, 14, 14] 264,192
│ │ └─ReLU: 3-51 [10, 1024, 14, 14] --
│ └─Block: 2-16 [10, 1024, 14, 14] --
│ │ └─Sequential: 3-52 [10, 256, 14, 14] 262,656
│ │ └─Sequential: 3-53 [10, 256, 14, 14] 590,336
│ │ └─Sequential: 3-54 [10, 1024, 14, 14] 264,192
│ │ └─ReLU: 3-55 [10, 1024, 14, 14] --
├─Sequential: 1-6 [10, 2048, 7, 7] --
│ └─Block: 2-17 [10, 2048, 7, 7] --
│ │ └─Sequential: 3-56 [10, 512, 14, 14] 525,312
│ │ └─Sequential: 3-57 [10, 512, 7, 7] 2,360,320
│ │ └─Sequential: 3-58 [10, 2048, 7, 7] 1,052,672
│ │ └─Sequential: 3-59 [10, 2048, 7, 7] 2,101,248
│ │ └─ReLU: 3-60 [10, 2048, 7, 7] --
│ └─Block: 2-18 [10, 2048, 7, 7] --
│ │ └─Sequential: 3-61 [10, 512, 7, 7] 1,049,600
│ │ └─Sequential: 3-62 [10, 512, 7, 7] 2,360,320
│ │ └─Sequential: 3-63 [10, 2048, 7, 7] 1,052,672
│ │ └─ReLU: 3-64 [10, 2048, 7, 7] --
│ └─Block: 2-19 [10, 2048, 7, 7] --
│ │ └─Sequential: 3-65 [10, 512, 7, 7] 1,049,600
│ │ └─Sequential: 3-66 [10, 512, 7, 7] 2,360,320
│ │ └─Sequential: 3-67 [10, 2048, 7, 7] 1,052,672
│ │ └─ReLU: 3-68 [10, 2048, 7, 7] --
├─AdaptiveAvgPool2d: 1-7 [10, 2048, 1, 1] --
├─Sequential: 1-8 [10, 1000] --
│ └─Linear: 2-20 [10, 1000] 2,049,000
==========================================================================================
Total params: 25,557,096
Trainable params: 25,557,096
Non-trainable params: 0
Total mult-adds (G): 40.90
==========================================================================================
Input size (MB): 6.02
Forward/backward pass size (MB): 1778.32
Params size (MB): 102.23
Estimated Total Size (MB): 1886.57
==========================================================================================from torch.utils.data import Dataset, DataLoader
from torchvision.transforms import transforms
import torchvision
import os
import numpy as np
import torch#超参数定义
# 批次的大小
batch_size = 16 #可选32、64、128
# 优化器的学习率
lr = 1e-4
#运行epoch
max_epochs = 2
# 方案一:指定GPU的方式
# os.environ['CUDA_VISIBLE_DEVICES'] = '0,1' # 指明调用的GPU为0,1号
# 方案二:使用“device”,后续对要使用GPU的变量用.to(device)即可
# device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # 指明调用的GPU为1号
# 数据读取
#cifar10数据集为例给出构建Dataset类的方式
from torchvision import datasets
#“data_transform”可以对图像进行一定的变换,如翻转、裁剪、归一化等操作,可自己定义
data_transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))
])
train_cifar_dataset = datasets.CIFAR10('cifar10',train=True, download=False,transform=data_transform)
test_cifar_dataset = datasets.CIFAR10('cifar10',train=False, download=False,transform=data_transform)
#构建好Dataset后,就可以使用DataLoader来按批次读入数据了
train_loader = torch.utils.data.DataLoader(train_cifar_dataset,
batch_size=batch_size, num_workers=4,
shuffle=True, drop_last=True)
test_loader = torch.utils.data.DataLoader(test_cifar_dataset,
batch_size=batch_size, num_workers=4,
shuffle=False)# from tensorboard import SummaryWriter
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter('./runs')#训练&验证
writer = SummaryWriter('./runs')
# Set fixed random number seed
torch.manual_seed(42)
# 定义损失函数和优化器
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
My_model = Resnet50()
My_model = My_model.to(device)
# 交叉熵
criterion = torch.nn.CrossEntropyLoss()
# 优化器
optimizer = torch.optim.Adam(My_model.parameters(), lr=lr)
epoch = max_epochs
total_step = len(train_loader)
train_all_loss = []
test_all_loss = []
for i in range(epoch):
My_model.train()
train_total_loss = 0
train_total_num = 0
train_total_correct = 0
for iter, (images,labels) in enumerate(train_loader):
images = images.to(device)
labels = labels.to(device)
# Write the network graph at epoch 0, batch 0
if epoch == 0 and iter == 0:
writer.add_graph(My_model, input_to_model=(images,labels)[0], verbose=True)
# Write an image at every batch 0
if iter == 0:
writer.add_image("Example input", images[0], global_step=epoch)
outputs = My_model(images)
loss = criterion(outputs,labels)
train_total_correct += (outputs.argmax(1) == labels).sum().item()
#backword
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_total_num += labels.shape[0]
train_total_loss += loss.item()
# Print statistics
writer.add_scalar("Loss/Minibatches", train_total_loss, train_total_num)
print("Epoch [{}/{}], Iter [{}/{}], train_loss:{:4f}".format(i+1,epoch,iter+1,total_step,loss.item()/labels.shape[0]))
# Write loss for epoch
writer.add_scalar("Loss/Epochs", train_total_loss, epoch)
My_model.eval()
test_total_loss = 0
test_total_correct = 0
test_total_num = 0
for iter,(images,labels) in enumerate(test_loader):
images = images.to(device)
labels = labels.to(device)
outputs = My_model(images)
loss = criterion(outputs,labels)
test_total_correct += (outputs.argmax(1) == labels).sum().item()
test_total_loss += loss.item()
test_total_num += labels.shape[0]
print("Epoch [{}/{}], train_loss:{:.4f}, train_acc:{:.4f}%, test_loss:{:.4f}, test_acc:{:.4f}%".format(
i+1, epoch, train_total_loss / train_total_num, train_total_correct / train_total_num * 100, test_total_loss / test_total_num, test_total_correct / test_total_num * 100
))
train_all_loss.append(np.round(train_total_loss / train_total_num,4))
test_all_loss.append(np.round(test_total_loss / test_total_num,4))#方法三:tensorboard查看
writer.add_graph(net,torch.rand(10, 3, 224, 224))
writer.close()4、知识补充
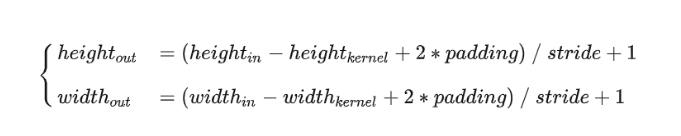
- input:
- shape(10, 3, 224, 224)
- 10:batch_size, 3:RGD ,224: width, 224:high
- conv:(in_depth=3, out_depth=64, kernel_size=7, stride=2, padding=3)
- output:
- width = (224-7+2*3)/2 + 1 = 112
- high = (224-7+2*3)/2 +1 = 112
- out_depth:64
- batch_dize:10
- shape:(10, 64, 112, 112)
阅读量:2102
点赞量:0
收藏量:0