知识点:详解激活函数-灵析社区
 GG
GG1. 激活函数的身影
每当复制代码的时候,经常发现一个叫激活函数的东西,看下面的代码:
model = Sequential([
Flatten(input_shape=(28,28)),
Dense(128, activation='relu'),
Dense(10, activation='softmax')
])
其中类似activation='relu'形状的,就是激活函数。
那么问题来了,为什么要有它?他能干啥?
2. 为什么需要激活函数?
2.1 神经元的加权求和
我们知道,人工智能的神经网络模仿的就是人类的神经元。
看,它有好多触角,每个触角都能接收到不同的信息,他们对信息也都有自己的判断,最终汇总到一起,然后继续往下传递,最终到大脑,你做出个决策:快跑!
单看某一个神经元,他的输入输出是这样的:Y = X1×W1+X2×W2+X3×W3。
到神经网络里面,只不过变成多维矩阵加权而已。
其实,这种工作方式是就是加权求和。

加权求和这种方式,是一个线性模型,它有一个局限,那就是无论多少层叠加,他都是一个线性模型。
线性模型解决不了非线性问题。
2.2 谁给解释下什么叫线性
多少篇文章,里面都说激活函数是为了去线性化。就这么一个“线性”,让多少小白折戟沉沙,从此再也不看人工智能。
那么这个线性到底指什么?
线性就是不拐弯,愣头青,没数。y = kx + b,随着变量变大,结果也变大。有多大变大多,有多小变多小,正负无穷。
但是,实际应用中,我们要的结果并不是这样。
举几个例子:
- 数字识别场景,不管输入多少张图片,我们要的输出就是10个分类:0~9。
- 电影评价情感分析,不管输入多少句评价,我们要的输出就是好评的概率。
- 股票预测,不管是牛市还是熊市,不会是涨跌到无限大,只会逼近某一个值。
现实生活中,很少有线性的事物,一个人再有钱,也是有数额的。都说头发无数根,其实也是有数量的。
所以,神经网络要应用到生活中,就必须去线性。因此,就需要在神经网络的层上再套一个激活函数。
可以来TensorFlow游乐场来试验下面的例子。
一条线可以轻松地把两种样本分离开来。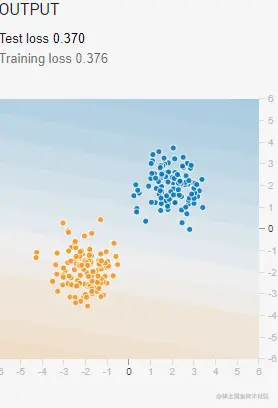
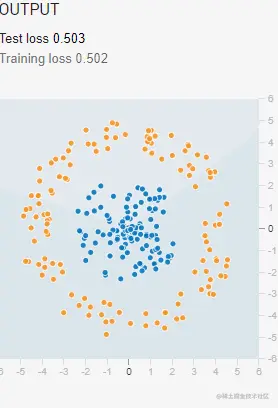
如果是下面的这种样本,一条直线是解决不了的。
如果在加权求和上再包一层激活函数:y=function(kx+b),变成函数套函数,这样就不是线性模型了,可以很轻易地区分。

把输入按照某种特定的规则映射到输出,这就是激活函数的作用。
下面这个高尔顿板,相当于在自由下落外面加了一层激活函数,就很形象地说明了它所起的作用。

如果换一种激活函数,输入都是一样,但是输出的分布却是另一种情况。

所以,不同的激活函数会有不同的效果,下面我们看看都有哪些激活函数。
3. 常见的激活函数
3.1 Sigmoid S型函数
sigmoid函数也叫Logistic函数,也是生物学中常见的一个函数,称为S型生长曲线。
记得生物老师讲过,当环境差时,生物种群增长缓慢。随着环境越来越好,生物种群快速增长。当增长到一定数量后,受到相互竞争的压力,种群数量趋于稳定。
因为它不是无限增长,另外它会将全部输入映射到0~1的区间内,所以在信息科学中,Sigmoid函数常被用作神经网络的激活函数,可以用来做二分法。
比如:做文本情感分析《NLP基础-中文语义理解:豆瓣影评情感分析》时,最后一层就用了sigmoid作为激活函数。
model = Sequential([
Embedding(vocab_size, embedding_dim, input_length= max_length),
GlobalAveragePooling1D(),
Dense(64, activation='relu'),
Dense(1, activation='sigmoid')
])
当输入一段文本后,最终输出1个数值,数值在0~1之间。0代表差评, 1代表好评。
"很好,演技不错", 0.91799414 ===>好评
"要是好就奇怪了", 0.19483969 ===>差评
"一星给字幕", 0.0028086603 ===>差评
"演技好,演技好,很差", 0.17192301 ===>差评
"演技好,演技好,演技好,演技好,很差" 0.8373259 ===>好评
3.2 tanh 双曲正切函数
tanh是双曲正切函数,下面是它的公式和图像。
它的形状和sigmoid有点像,只不过输出区间变成了-1到1。
相比sigmoid,它很好地解决了以0为中心的问题。
3.3 ReLU 线性整流函数
ReLU称为线性整流函数(Rectified Linear Unit),又称修正线性单元。

相比于sigmoid和tanh,线性整流函数有很多优势:
- 更接近仿生学:大脑同一时间大概只有1%~4%的神经元处于活跃状态。使用relu函数可以实现对神经元活跃度的控制。
- 计算过程更简单:没有其他函数的指数运算。同时,因为神经元的活跃度分散,使得计算成本下降。
如果你构建神经网络时,不知道该用哪个激活函数,那就用ReLU。
3.4 softmax 归一化指数函数
softmax被称为归一化指数函数,它是在sigmoid二分类上进行的多分类推广,目的是将多分类的结果以概率的形式展现出来。
softmax在业内一直有一个争议点:它算不算激活函数?
从我这里看,它算式一个激活函数。

Softmax主要解决多类别分类问题,解决只有唯一正确答案的问题,它以概率形式输出多个分类的可能性,输出是互斥的,所有输出的概率和接近1。
比如手写数字识别,最后一层就是用的softmax:Dense(10, activation='softmax'),输出0~9这10个分类的概率。
[[2.3691061e-11 1.0000000e+00 5.5736946e-14 1.7459076e-10 1.8988343e-13
8.0071365e-31 1.2010425e-14 0.0000000e+00 6.0655720e-20 1.8470960e-27]]
然后调用np.argmax(p)就可以得出概率列表中最大概率的索引是1。
以上就是关于激活函数的知识点。
阅读量:2121
点赞量:0
收藏量:0