2.索引-灵析社区
 菜鸟码转
菜鸟码转一、索引的优缺点
索引的优点
- 通过创建 唯一性索引,可以保证数据库表中每一行数据的唯一性;
- 可以加快数据的 检索速度,这也是创建索引的主要原因;
- 可以加速表和表之间的连接,特别是在实现 数据的参考完整性 方面特别有意义;
- 通过使用索引,可以在查询的过程中,使用 优化隐藏器,提高系统性能。
索引的缺点
- 时间上,创建和维护索引都要耗费时间,这种时间随着数据量的增加而增加,具体地,当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度;
- 空间上,索引需要占 物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大。
二、索引的数据结构
数据库索引根据结构分类,主要有 B 树索引、Hash 索引 和 位图索引 三种。
B 树索引
B 树索引,又称 平衡树索引,是 MySQL 数据库中使用最频繁的索引类型,MySQL、Oracle 和 SQL Server 数据库默认的都是 B 树索引(实际是用 B+ 树实现的,因为在查看表索引时,MySQL 一律打印 BTREE,所以简称为 B 树索引)。
B 树索引以 树结构 组织,它有一个或者多个分支结点,分支结点又指向单级的叶结点。其中,分支结点用于遍历树,叶结点则保存真正的值和位置信息。
B+ 树是在 B 树基础上的一种优化,使其更适合实现外存储索引结构。
一棵 m 阶 B-Tree 的特性如下:
- 每个结点最多 m 个子结点;
- 除了根结点和叶子结点外,每个结点最少有 m/2(向上取整)个子结点;
- 所有的叶子结点都位于同一层;
- 每个结点都包含 k 个元素(关键字),这里 m/2≤k<m,这里 m/2 向下取整;
- 每个节点中的元素(关键字)从小到大排列;
- 每个元素子左结点的值,都小于或等于该元素,右结点的值都大于或等于该元素。
数据库以 B-Tree 的数据结构存储数据的图示如下:

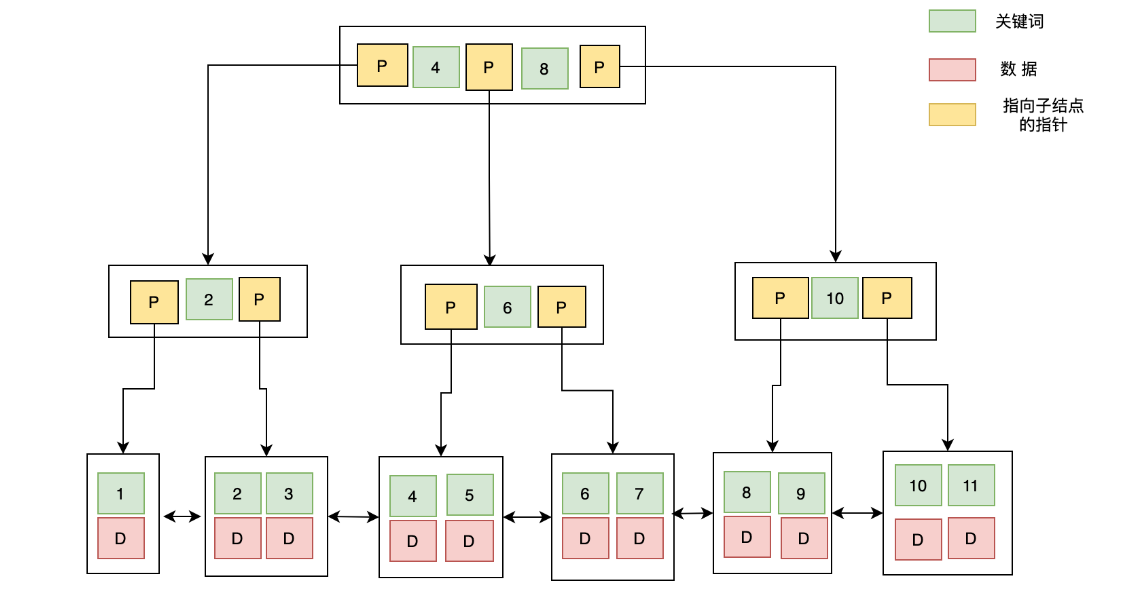
B+ Tree 与 B-Tree 的结构很像,但是也有自己的特性:
所有的非叶子结点只存储 关键字信息;
所有具体数据都存在叶子结点中;
所有的叶子结点中包含了全部元素的信息;
所有叶子节点之间都有一个链指针。
数据库以 B+ Tree 的数据结构存储数据的图示如下:
Hash 索引
哈希索引采用一定的 哈希算法(常见哈希算法有 直接定址法、平方取中法、折叠法、除数取余法、随机数法),将数据库字段数据转换成定长的 Hash 值,与这条数据的行指针一并存入 Hash 表的对应位置,如果发生 Hash 碰撞(两个不同关键字的 Hash 值相同),则在对应 Hash 键下以 链表形式 存储。
检索时不需要类似 B+ 树那样从根节点到叶子节点逐级查找,只需一次哈希算法即可立刻定位到相应的位置,速度非常快,平均检索时间为 O(1)。
位图索引
B 树索引擅长于处理包含许多不同值的列,但是在处理基数较小的列时会变得很难使用。如果用户查询的列的基数非常的小, 即只有几个固定值,如性别、婚姻状况、行政区等等,要么不使用索引,查询时一行行扫描所有记录,要么考虑建立位图索引。
位图索引为存储在某列中的每个值生成一个位图。例如针对表中婚姻状况这一列,生成的位图索引大致如下所示:

对于婚姻状况这一列,索引包含 3 个位图,即生成有 3 个向量,分别属于每一个取值,每个位图为每一个人(行)都分配了 0/1 值(每一行有且仅有一个 1 ),未婚为 110000……,已婚为 000111……,离婚为 001000……。
当进行数据查找时,只要查找相关位图中的所有 1 值即可(可根据查询需求进行与、或运算)。
例如, Oracle 用户可以通过为 create index 语句简单地添加关键词 bitmap 生成位图:
CREATE BITMAP INDEX acc_marital_idx ON account (marital_cd);除了上述提及的,位图索引适合只有几个固定值的列,还需注意 ,位图索引适合静态数据,而不适合索引频繁更新的列。
三、使用 B+ 树的好处
- 由于 B+ 树的内部结点只存放键,不存放值,因此,一次读取,可以在同一内存页中获取更多的键,有利于更快地缩小查找范围。
- B+ 树的叶结点由一条链相连,因此当需要进行一次 全数据遍历 的时候,B+ 树只需要使用 O(logN) 时间找到最小结点,然后通过链进行 O(N) 的顺序遍历即可;或者,在找 大于某个关键字或者小于某个关键字的数据 的时候,B+ 树只需要找到该关键字然后沿着链表遍历即可。
四、Hash 索引和 B+ 树索引的区别
Hash 索引和 B+ 树索引有以下几点显见的区别:
- Hash 索引进行等值查询更快(一般情况下),但是却无法进行范围查询;
- Hash 索引不支持使用索引进行排序;
- Hash 索引不支持模糊查询以及多列索引的最左前缀匹配,原理也是因为 Hash 函数的不可预测;
- Hash 索引任何时候都避免不了回表查询数据,而 B+ 树在符合某些条件(聚簇索引,覆盖索引等)的时候可以只通过索引完成查询;
- Hash 索引虽然在等值查询上较快,但是不稳定,性能不可预测,当某个键值存在大量重复的时候,发生 Hash 碰撞,此时效率可能极差;而 B+ 树的查询效率比较稳定,对于所有的查询都是从根结点到叶子结点,且树的高度较低。
五、什么是前缀索引
有时需要索引很长的字符列,它会使索引变大并且变慢,一个策略就是索引开始的几个字符,而不是全部值,即被称为 前缀索引,以节约空间并得到好的性能。使用前缀索引的前提是 此前缀的标识度高,比如密码就适合建立前缀索引,因为密码几乎各不相同。
前缀索引需要的空间变小,但也会降低选择性。索引选择性(INDEX SELECTIVITY)是不重复的索引值(也叫基数)和表中所有行数(T)的比值,数值范围为 1/T ~1。高选择性的索引有好处,因为在查找匹配的时候可以过滤掉更多的行,唯一索引的选择率为 1,为最佳值。对于前缀索引而言,前缀越长往往会得到好的选择性,但是短的前缀会节约空间,所以实操的难度在于前缀截取长度的抉择,可以通过调试查看不同前缀长度的 平均匹配度,来选择截取长度。
六、什么是最左前缀匹配原则
在 MySQL 建立 联合索引(多列索引) 时会遵守最左前缀匹配原则,即 最左优先,在检索数据时从联合索引的最左边开始匹配。例如有一个 3 列索引(a,b,c),则已经对(a)、(a,b)、(a,b,c)上建立了索引。所以在创建 多列索引时,要根据业务需求,where 子句中 使用最频繁 的一列放在最左边。
根据最左前缀匹配原则,MySQL 会一直向右匹配直到遇到 范围查询(>、<、between、like)就停止匹配,比如采用查询条件 where a = 1 and b = 2 and c > 3 and d = 4 时,如果建立(a,b,c,d)顺序的索引,d 是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,并且 where 子句中 a、b、d 的顺序可以任意调整。
如果建立的索引顺序是 (a,b) ,那么根据最左前缀匹配原则,直接采用查询条件 where b = 1 是无法利用到索引的。
七、添加索引的原则
索引虽好,但也不是无限制使用的,以下为添加索引时需要遵循的几项建议性原则:
- 在 查询中很少使用 或者参考的列不要创建索引。由于这些列很少使用到,增加索引反而会降低系统的维护速度和增大空间需求。
- 只有很少数据值的列 也不应该增加索引。由于这些列的取值很少,区分度太低,例如人事表中的性别,在查询时,需要在表中搜索的数据行的比例很大。增加索引,并不能明显加快检索速度。
- 定义为 text、image 和 bit 数据类型的列不应该增加索引。这是因为,这些列的数据量要么相当大,要么取值很少。
- 当 修改性能远远大于检索性能 时,不应该创建索引。这时因为,二者是相互矛盾的,当增加索引时,会提高检索性能,但是会降低修改性能。
- 定义有 外键 的数据列一定要创建索引。
八、什么是聚簇索引
聚簇索引,又称 聚集索引, 首先并不是一种索引类型,而是一种数据存储方式。具体的,聚簇索引指将 数据存储 和 索引 放到一起,找到索引也就找到了数据。
MySQL 里只有 INNODB 表支持聚簇索引,INNODB 表数据本身就是聚簇索引,非叶子节点按照主键顺序存放,叶子节点存放主键以及对应的行记录。所以对 INNODB 表进行全表顺序扫描会非常快。
特点
因为索引和数据存放在一起,所以具有更高的检索效率;
相比于非聚簇索引,聚簇索引可以减少磁盘的 IO 次数;
表的物理存储依据聚簇索引的结构,所以一个数据表只能有一个聚簇索引,但可以拥有多个非聚簇索引;
一般而言,会在频繁使用、排序的字段上创建聚簇索引。
非聚簇索引
除了聚簇索引以外的其他索引,均称之为非聚簇索引。非聚簇索引也是 B 树结构,与聚簇索引的存储结构不同之处在于,非聚簇索引中不存储真正的数据行,只包含一个指向数据行的指针。
就简单的 SQL 查询来看,分为 SELECT 和 WHERE 两个部分,索引的创建也是以此为根据的,分为 复合索引 和 覆盖索引。
阅读量:2138
点赞量:0
收藏量:0